최근 멀티모달(Multimodal) AI 분야에서는 거대한 언어 모델(LLM)과 비전 모델을 어떻게 효율적으로 결합할 것인지가 중요한 화두입니다. DeepMind가 제안한 Flamingo 모델은 기존에 잘 학습된 거대 모델들의 가중치를 그대로 유지하면서도, 시각 정보를 자연스럽게 텍스트 생성 과정에 녹여내는 독창적인 구조를 제시했습니다.
관련 논문: https://arxiv.org/abs/2204.14198
Flamingo: a Visual Language Model for Few-Shot Learning
Building models that can be rapidly adapted to novel tasks using only a handful of annotated examples is an open challenge for multimodal machine learning research. We introduce Flamingo, a family of Visual Language Models (VLM) with this ability. We propo
arxiv.org
1. Flamingo란?
Flamingo는 텍스트와 이미지가 혼합된 입력을 받아들여 텍스트로 응답하는 대규모 멀티모달 모델(Large Multimodal Model, LMM)입니다.
기존의 많은 멀티모달 모델들이 텍스트와 이미지 데이터를 처음부터 함께 학습시키는 방식을 취했다면, Flamingo는 사전학습된 Vision Encoder와 대형 언어모델(LLM)을 고정한 채, 그 사이에 새로운 레이어를 삽입하여 이미지 정보를 텍스트 생성 과정에 주입하는 방식을 사용합니다. 이를 통해 기존 LLM이 가진 강력한 언어 능력을 손실 없이 그대로 활용하면서도, 시각 정보를 조건으로 통합할 수 있습니다.
2. BLIP vs. Flamingo
멀티모달 모델의 발전 과정을 이해하기 위해, 이미지 캡셔닝과 VQA(Visual Question Answering) 등에서 널리 쓰이는 BLIP과 Flamingo를 비교해 볼 수 있습니다. 두 모델은 구조적 철학과 활용 목적에서 뚜렷한 차이를 보입니다.
BLIP (직접 학습 및 통합 방식):
- 구조: 이미지와 텍스트를 함께 학습하는 Encoder-Decoder 기반 모델입니다.
- 특징: Vision Encoder와 Text Encoder/Decoder를 아키텍처 레벨에서 함께 파인튜닝(Fine-tuning)하며 학습시킵니다.
- 목적: 이미지 캡셔닝, VQA 등 특정 멀티모달 태스크에 최적화된 성능을 끌어내는 데 집중합니다.
Flamingo (주입 및 Few-shot 방식):
- 구조: 강력한 사전학습 LLM을 중심축으로 두고, 시각 정보를 "끼워 넣는(Plug-in)" 방식입니다.
- 특징: 두 거대 모델(Vision, LLM)의 파라미터를 동결하고, 중간의 Cross-Attention 레이어만 학습시킵니다.
- 목적: 여러 장의 이미지와 긴 문맥을 활용한 Few-shot 추론 능력을 극대화하는 것이 핵심 강점입니다. 별도의 태스크별 파인튜닝 없이도 프롬프트만으로 다양한 상황에 대처할 수 있습니다.
3. Flamingo의 핵심 아키텍처
Flamingo의 구조는 크게 세 가지 핵심 컴포넌트로 나눌 수 있습니다.
3.1 Vision Encoder (고정/Freeze)
- 역할: 입력된 이미지로부터 시각적 특징(Feature)을 추출합니다.
- 특징: CLIP(Contrastive Language-Image Pretraining)의 Vision Encoder와 같은 강력한 사전학습 모델을 사용하며, Flamingo 학습 과정에서는 가중치를 업데이트하지 않고 고정(Freeze)합니다.
3.2 Large Language Model (고정/Freeze)
- 역할: 언어를 이해하고 텍스트를 생성하는 두뇌 역할을 합니다.
- 특징: DeepMind의 Chinchilla와 같은 대형 언어 모델을 기반으로 합니다. Vision Encoder와 마찬가지로 가중치를 동결하여, 모델이 사전에 학습한 방대한 지식과 추론 능력이 손상되는 것(Catastrophic Forgetting)을 방지합니다.
3.3. Gated Cross-Attention Layer (학습/Trainable)
- 역할: 고정된 LLM 내부의 Transformer 블록들 사이에 삽입되어, Vision Encoder에서 추출된 이미지 정보를 LLM에 주입하는 역할을 합니다.
- 특징: 'Gating' 메커니즘을 사용하여 초기화 시점에는 기존 LLM의 출력과 동일하게 작동하도록 설정됩니다. 학습이 진행됨에 따라 점진적으로 시각적 정보가 텍스트 생성에 얼마나 반영될지를 조절하게 됩니다. 이 레이어 덕분에 이미지 정보를 조건으로 받아들일 수 있습니다.
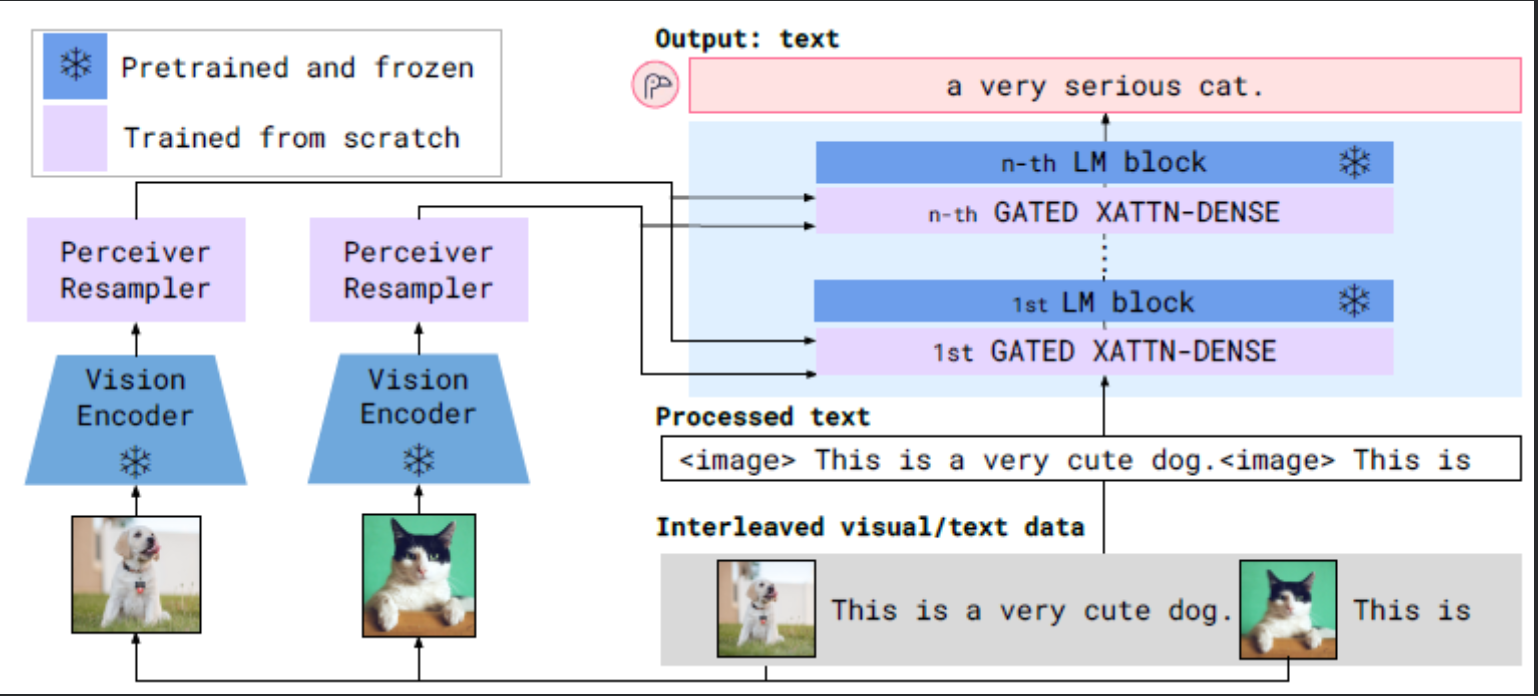
4. Flamingo: Few-shot 멀티모달 추론
Flamingo가 다른 모델들과 차별화되는 가장 큰 특징은 인터리브드(Interleaved) 데이터, 즉 텍스트와 이미지가 번갈아 나오는 긴 문맥을 이해하고 유지할 수 있다는 점입니다.
이를 통해 사용자는 텍스트 LLM에서 하던 것과 동일하게 Few-shot Prompting을 멀티모달 환경에서 수행할 수 있습니다.
Few-shot Prompt 예시 [Image1] 이것은 고양이입니다. [Image2] 이것은 강아지입니다. [Image3] 이것은 무엇인가요? Model Output: 햄스터입니다.

단순히 한 장의 이미지에 대한 질문에 답하는 것을 넘어, 위와 같이 여러 장의 이미지와 그에 대한 설명(예시)을 문맥으로 제공하면, 모델이 그 패턴을 인식하고 마지막 질문(새로운 이미지)에 대해 정확한 답변을 생성해 냅니다.
'개념 정리 step2 > 멀티모달(Multi-modal)' 카테고리의 다른 글
| [멀티 모달] InstructGPT부터 LLaVA까지 정리본 (0) | 2026.02.19 |
|---|---|
| [멀티모달] BLIP & BLIP-2 핵심 구조 및 실습 코드 정리 (0) | 2026.02.17 |
| [비전 AI] 텍스트로 객체를 찾는 Zero-Shot Detection부터 GroundingDINO까지 (0) | 2026.02.14 |
| [머신러닝] 차원 축소 PCA, t-SNE, UMAP부터 CLIP 시각화까지 (0) | 2026.02.13 |
| [Vision-Language] CLIP 모델 핵심 정리 및 유사도 히트맵 실습 (0) | 2026.02.11 |