오늘 정리한 내용은 객체 탐지(Object Detection) 분야의 최신 트렌드이자 패러다임 전환을 보여주는 매우 중요한 주제입니다. 기존의 고정된 클래스를 넘어서, 텍스트로 원하는 객체를 자유롭게 찾아내는 과정(DETR → DINO → GroundingDINO)을 정리해봤습니다.
기존의 객체 탐지(Object Detection) 모델들은 미리 학습된 80개, 혹은 1000개의 고정된 클래스만 찾을 수 있었습니다. 만약 모델이 '고양이'와 '개'만 학습했다면, 사진 속에 있는 '판다'나 '리모컨'은 절대 찾아낼 수 없었습니다.
하지만 멀티모달(Multimodal) AI가 발전하면서, "텍스트로 설명만 해주면 처음 보는 객체도 찾아내는" 기술이 등장했습니다. 오늘은 객체 탐지의 판도를 바꾼 Zero-Shot Object Detection의 개념부터, 이를 가능하게 한 DETR, DINO, 그리고 최신 모델인 GroundingDINO의 실전 파이썬 코드까지 단계별로 알아보겠습니다.
1. Zero-Shot Object Detection과 Open-Vocabulary
기존 Object Detection의 한계
일반적인 객체 탐지 모델(YOLO, Faster R-CNN 등)은 예측할 수 있는 클래스가 학습 시점에 고정됩니다.
- 구조: 이미지 → 특징 추출 → 바운딩 박스 예측 + 고정 클래스 분류
- 문제점: 학습 데이터에 없는 새로운 객체를 탐지하려면 데이터 수집부터 모델 재학습까지 처음부터 다시 해야 합니다. 현실 세계의 객체는 무한한데, 이를 모두 학습시키는 것은 불가능합니다.
Zero-Shot Detection의 핵심 아이디어
Zero-Shot Detection은 이미지와 텍스트를 같은 의미 공간(Embedding Space)에 매핑하여 이 한계를 극복합니다.
- 동작 방식: 이미지를 벡터로, 텍스트를 벡터로 변환한 뒤 두 벡터의 유사도를 계산합니다.
- 즉, 고정된 분류기(Classifier)를 거치는 것이 아니라, "이 이미지 영역이 입력된 텍스트 설명과 얼마나 유사한가?"를 계산하여 클래스를 결정합니다.
Open-Vocabulary
이러한 방식을 통해 모델은 사전에 닫힌(Class-closed) 구조를 벗어나, 계속해서 확장 가능한 열린(Open) 개념 체계를 다룰 수 있게 됩니다. 이를 Open-Vocabulary라고 부르며, 텍스트로 새롭게 정의되는 개념까지 유연하게 인식할 수 있는 능력을 의미합니다.
2. DETR (DEtection TRansformer)
이러한 혁신적인 탐지 모델의 뼈대가 되는 기술 중 하나가 바로 DETR입니다. DETR은 복잡했던 객체 탐지 파이프라인을 Transformer를 이용해 아주 단순하고 우아하게 바꾼 End-to-End 모델입니다.

핵심 개념 1: Object Query
기존 모델들이 화면 전체에 무수히 많은 앵커 박스(Anchor Box)를 깔아두고 시작했다면, DETR은 Object Query라는 학습 가능한 질의 벡터를 사용합니다.
- 미리 정해진 개수(예: 100개)의 슬롯(Query)이 Transformer Decoder에 입력됩니다.
- 각 Query는 이미지의 문맥을 살피며 "여기에 객체가 있나?"를 질문하고, 클래스와 바운딩 박스를 동시에 직접 예측합니다.
핵심 개념 2: Hungarian Matching
DETR은 고정된 개수의 예측 집합(Set)을 한 번에 쏟아냅니다. 이때 어떤 예측이 실제 정답(Ground Truth)과 매칭되는지 1:1로 최적의 짝을 찾아주는 알고리즘이 Hungarian Matching입니다. 이를 통해 중복 예측을 없애고, 복잡한 NMS(Non-Maximum Suppression) 후처리 과정 없이도 학습이 가능해졌습니다.
3. DINO (Detection with Improved DeNoising Anchor Boxes)
DETR은 혁신적이었지만, 초기 Object Query가 어디를 봐야 할지 모른 채 학습을 시작하기 때문에 수렴 속도가 너무 느리다는 치명적인 단점이 있었습니다. 이를 해결한 것이 DINO입니다.
DINO의 강력한 무기: Denoising Training
DINO는 정답 박스 좌표에 약간의 노이즈(오차)를 섞은 뒤, 이를 모델에 입력하여 "원래 정답 위치로 복원(Denoising)"하도록 학습시킵니다. 이 방식을 통해 모델은 초기부터 박스를 어떻게 조정해야 하는지 빠르게 깨닫게 되며, DETR의 고질적인 문제였던 느린 학습 속도와 작은 객체 탐지 성능 저하를 획기적으로 해결했습니다.
💡 참고: Swin Transformer 비전 모델의 백본(Backbone)으로 자주 쓰이는 구조입니다. 기존 ViT가 전체 이미지를 한 번에 처리해 연산량이 컸다면, Swin은 이미지를 윈도우 단위로 쪼개고 층이 깊어질수록 윈도우를 이동(Shift)시키며 전역 정보를 통합합니다. 연산 효율이 좋고 멀티스케일 탐지에 강력합니다.
Swin Transformer에 대한 논문:
https://arxiv.org/pdf/2103.14030

4. GroundingDINO: 텍스트로 객체를 짚어내다
대망의 GroundingDINO는 강력한 객체 탐지기인 DINO에 텍스트 인코더를 결합한 Open-Vocabulary 모델입니다.
GrundingDINO: 참고 논문
https://arxiv.org/pdf/2303.05499

"Grounding(접지)"의 의미
단순한 분류를 넘어, 입력된 언어(단어/구문)를 이미지 내의 특정 영역(Bounding Box)에 정확히 연결(매칭)하는 작업을 뜻합니다.
- 입력: 이미지 + 텍스트 ("a cat. a remote control.")
- 출력: 텍스트에 해당하는 각각의 객체 박스와 매칭 점수(Score)
이제 사전 학습된 클래스 목록은 필요 없습니다. 우리가 말하는 대로 모델이 찾아줍니다.
실전 코드: GroundingDINO로 이미지 탐지하기
Hugging Face의 transformers 라이브러리를 활용해 GroundingDINO를 직접 실행해 보는 코드입니다.
import requests
import torch
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from PIL import Image
from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
# 1. 디바이스 및 모델 로드
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model_id = 'IDEA-Research/grounding-dino-base'
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to(device)
model.eval()
# 2. 이미지 및 텍스트 프롬프트 준비
image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(image_url, stream=True).raw).convert("RGB")
text = 'a cat. a remote control.' # 찾고자 하는 객체를 마침표로 구분하여 입력
# 3. 모델 추론
inputs = processor(images=image, text=text, return_tensors='pt').to(device)
with torch.no_grad():
outputs = model(**inputs)
# 4. 결과 후처리 (박스, 점수, 라벨 추출)
results = processor.post_process_grounded_object_detection(
outputs=outputs,
input_ids=inputs.input_ids,
box_threshold=0.25, # 박스 신뢰도 임계값
text_threshold=0.2, # 텍스트 매칭 신뢰도 임계값
target_sizes=[image.size[::-1]] # (H, W) 형태로 전달
)
# 5. 시각화
fig, ax = plt.subplots(1, figsize=(10, 8))
ax.imshow(image)
for score, box, label in zip(
results[0]['scores'].cpu(),
results[0]['boxes'].cpu(),
results[0]['text_labels']
):
x_min, y_min, x_max, y_max = box.tolist()
width, height = x_max - x_min, y_max - y_min
# 바운딩 박스 그리기
rect = patches.Rectangle(
(x_min, y_min), width, height,
linewidth=2, edgecolor='red', facecolor='none'
)
ax.add_patch(rect)
# 라벨 및 점수 텍스트 추가
caption = f'{label} ({score:.2f})'
ax.text(
x_min, max(0, y_min - 5), caption,
fontsize=12, color='white',
bbox=dict(facecolor='red', alpha=0.5, edgecolor='none', boxstyle='round,pad=0.3')
)
ax.axis("off")
out_path = "grounding_dino_result.png"
plt.tight_layout()
plt.savefig(out_path, dpi=200, bbox_inches="tight")
plt.show()
print(f"Saved: {out_path}")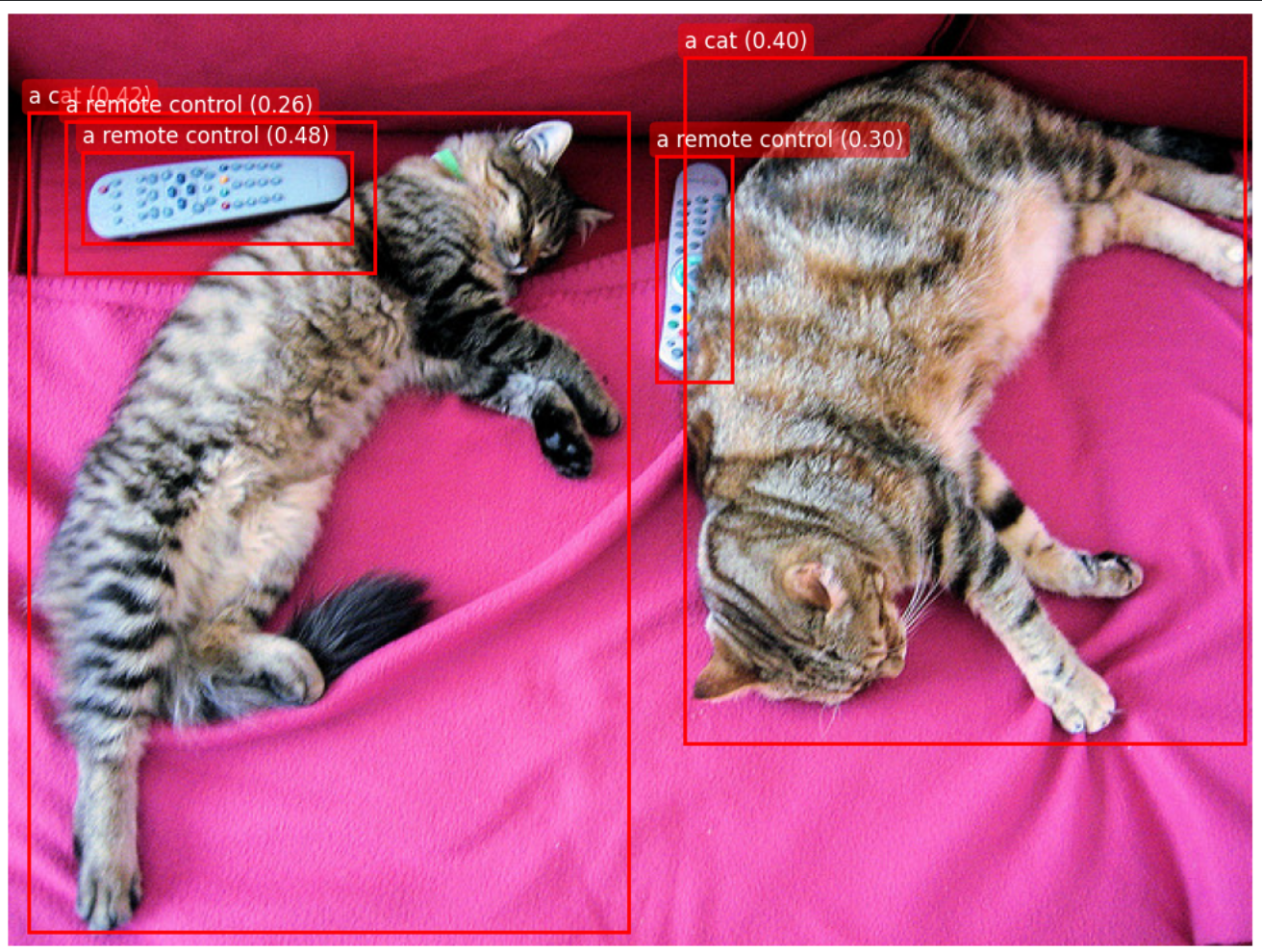
'개념 정리 step2 > 멀티모달(Multi-modal)' 카테고리의 다른 글
| [멀티 모달] DeepMind Flamingo: 언어 모델에 시각 능력을 부여하는 멀티모달 모델 (0) | 2026.02.19 |
|---|---|
| [멀티모달] BLIP & BLIP-2 핵심 구조 및 실습 코드 정리 (0) | 2026.02.17 |
| [머신러닝] 차원 축소 PCA, t-SNE, UMAP부터 CLIP 시각화까지 (0) | 2026.02.13 |
| [Vision-Language] CLIP 모델 핵심 정리 및 유사도 히트맵 실습 (0) | 2026.02.11 |
| [멀티모달] Multimodal Learning 정리 (0) | 2026.02.10 |