1. BLIP (Bootstrapping Language-Image Pretraining)
BLIP은 이미지와 텍스트를 함께 학습하는 Vision-Language 모델입니다. 이미지 캡셔닝과 이미지-텍스트 매칭을 동시에 수행할 수 있도록 설계된 멀티모달 사전학습 모델입니다.
이미지 인코더와 텍스트 인코더를 결합해 이미지와 문장을 같은 표현 공간에 정렬합니다. 특히 노이즈가 많은 웹 데이터 환경에서도 자동 캡션 생성과 필터링을 통해 학습 데이터를 정제하는 “Bootstrapping” 전략을 사용하여 다양한 멀티모달 작업(이미지 캡셔닝, 텍스트-이미지 검색, VQA 등)에서 강력한 성능을 자랑합니다.
논문 링크:
https://arxiv.org/abs/2201.12086
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks. However, most existing pre-trained models only excel in either understanding-based tasks or generation-based tasks. Furthermore, performance improvement has bee
arxiv.org
1-1. Bootstrapping의 핵심 의미
웹에서 수집한 이미지-텍스트 쌍 데이터는 캡션이 부정확하거나 이미지와 맞지 않는 노이즈가 매우 많습니다. BLIP은 이를 해결하기 위해 모델이 스스로 캡션을 생성하고, 그중 품질이 좋은 데이터를 선별해 다시 학습에 사용하는 전략을 도입했습니다. 즉, 데이터를 스스로 정제하며 학습을 개선하는 선순환 구조입니다.
- Bootstrapping 4단계 프로세스
- 초기 모델을 사용하여 이미지에 대한 캡션 생성
- 생성된 캡션과 원래 웹 캡션을 비교
- 노이즈를 필터링하고 품질 좋은 샘플만 선별
- 선별된 고품질 데이터로 모델 재학습
1-2. BLIP의 전체 아키텍처 구조
- Vision Encoder: 이미지를 특징 벡터로 변환
- ViT 기반 구조 사용
- 이미지를 패치 단위로 나누어 Transformer로 처리
- 최종적으로 이미지 임베딩 출력
- Text Encoder: 텍스트를 임베딩 벡터로 변환
- BERT 스타일의 Transformer 구조 사용
- 텍스트를 토큰 단위로 인코딩하여 임베딩 출력
- Multimodal Encoder / Decoder
- 이미지 특징과 텍스트 특징을 함께 처리하는 결합 모듈
- Cross-Attention을 통해 두 가지 모달리티를 효과적으로 결합
- 이를 통해 이미지-텍스트 매칭 및 고품질 이미지 캡션 생성이 가능

2. BLIP-2: 대형 언어모델(LLM)과의 효율적인 연결
기존 Vision-Language 모델들은 이미지 인코더, 텍스트 인코더, 멀티모달 인코더를 처음부터 모두 새로 학습해야 했습니다. 이는 수억에서 수십억 개의 방대한 데이터가 필요하고 연산량이 매우 크며, 무엇보다 이미 잘 만들어진 대형 언어모델을 활용하기 위해 처음부터 다시 학습시켜야 한다는 치명적인 단점이 있었습니다.
BLIP-2는 “이미 잘 학습된 거대 모델들은 그대로 두고, 그 사이의 연결만 잘하자”라는 혁신적인 전략을 취합니다. 기존 인코더와 대형 언어모델을 직접 미세조정하지 않고, 그 사이에 Q-Former(Querying Transformer)라는 가벼운 중간 모듈을 두어 두 모델을 연결합니다.
논문 링크:
https://arxiv.org/abs/2301.12597
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
The cost of vision-and-language pre-training has become increasingly prohibitive due to end-to-end training of large-scale models. This paper proposes BLIP-2, a generic and efficient pre-training strategy that bootstraps vision-language pre-training from o
arxiv.org
2-1. BLIP-2의 핵심 아이디어 및 구조
- Pretrained Vision Encoder (가중치 고정)
- ViT, CLIP Vision Encoder 등 이미 학습된 강력한 시각 모델 사용
- Pretrained LLM (가중치 고정)
- OPT, Flan-T5 등의 대형 언어모델 사용
- Q-Former (이 모듈만 학습)
- 이미지 정보를 언어모델이 이해할 수 있는 언어적 형태로 번역해 주는 '중간 통역사' 역할
2-2. Q-Former 파헤치기
Q-Former는 “이미지에서 언어모델이 이해할 수 있는 핵심 정보만 뽑아주는 압축기”입니다.
- 소수의 학습 가능한 쿼리 벡터(예: 32개)를 배치합니다.
- 이 쿼리들이 고정된 Vision Encoder에서 나온 이미지 특징과 Cross-Attention 연산을 수행합니다.
- 이미지에서 가장 중요한 정보만 추출하여, 언어모델에 전달할 수 있는 작고 밀도 높은 특징 집합을 생성합니다.
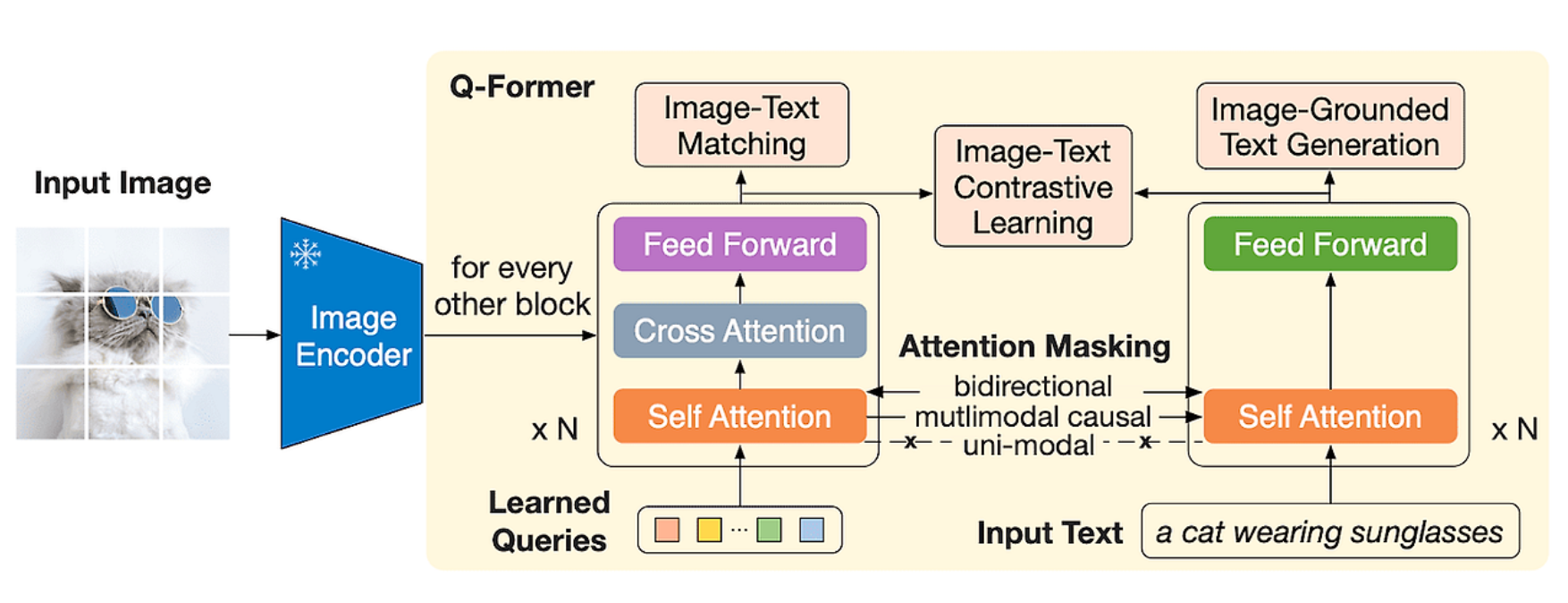
2-3. BLIP-2의 2단계 학습 전략
- 1단계: 시각-언어 표현 학습
- 고정된 Vision Encoder와 학습 가능한 Q-Former를 연결하여 학습합니다.
- 이미지-텍스트 매칭, 이미지 캡셔닝 등의 태스크를 수행합니다.
- 👉 목적: Q-Former가 이미지와 텍스트 간의 정렬을 완벽하게 학습하도록 만듭니다.
- 2단계: LLM 연결 학습
- Q-Former의 출력을 고정된 대형 언어모델의 입력으로 바로 연결합니다.
- 이때도 언어모델은 가중치를 고정하고 오직 Q-Former만 학습시킵니다.
- 👉 목적: 시각적 정보가 주입되었을 때, 언어모델이 이미지를 깊이 이해하고 관련된 텍스트를 생성할 수 있도록 만듭니다.
3. [실습] BLIP vs CLIP: 텍스트 → 이미지 검색 성능 비교
BLIP과 대표적인 대조학습 기반 모델인 CLIP의 텍스트 기반 이미지 검색 성능을 비교하는 코드입니다.
import torch
import numpy as np
import io
from PIL import Image
from datasets import load_dataset
from transformers import BlipProcessor, BlipForImageTextRetrieval
from transformers import CLIPProcessor, CLIPModel
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"Using device: {device}")
# ==========================================
# 1. 모델 로드 (BLIP & CLIP)
# ==========================================
# BLIP 모델 준비
blip_processor = BlipProcessor.from_pretrained('Salesforce/blip-itm-base-coco')
blip_model = BlipForImageTextRetrieval.from_pretrained('Salesforce/blip-itm-base-coco').to(device)
blip_model.eval()
# CLIP 모델 준비
clip_model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32").to(device)
clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
clip_model.eval()
# ==========================================
# 2. 데이터 전처리 유틸리티 함수
# ==========================================
# 텍스트 정규화: 다양한 타입의 캡션 데이터를 순수 문자열로 통일
def normalize_caption(x):
if x is None: return ""
if isinstance(x, (bytes, bytearray)): return x.decode('utf-8', errors='ignore')
if isinstance(x, dict):
for k in ['text', 'caption', 'txt', 'value']:
if k in x and isinstance(x[k], str): return x[k]
return str(x)
if isinstance(x, (list, tuple)):
for item in x:
if isinstance(item, str): return item
return str(x)
return str(x) if not isinstance(x, str) else x
# 이미지 정규화: 경로, 바이트 등 다양한 형태의 이미지를 PIL RGB 객체로 통일
def to_pil(x):
if isinstance(x, Image.Image): return x.convert('RGB')
if isinstance(x, dict) and 'bytes' in x and x['bytes'] is not None:
return Image.open(io.BytesIO(x['bytes'])).convert('RGB')
if isinstance(x, str):
return Image.open(x).convert('RGB')
raise TypeError(f'지원하지 않는 이미지 형식: {type(x)}')
# L2 정규화 (코사인 유사도 계산용)
def l2_normalize(x: np.ndarray, axis: int=-1, eps: float = 1e-12):
return x / (np.linalg.norm(x, axis=axis, keepdims=True) + eps)
# Top-K 성능 평가 함수
def evaluate_retrieval(similarity_matrix: np.ndarray, top_k=(1, 5, 10)):
num_samples = similarity_matrix.shape[0]
ranks = []
for i in range(num_samples):
sorted_idx = np.argsort(similarity_matrix[i])[::-1] # 내림차순 정렬
rank_pos = int(np.where(sorted_idx == i)[0][0]) # 정답 이미지의 순위 파악
ranks.append(rank_pos)
return {f'Top-{k}': float(np.mean(np.array(ranks) < k)) for k in top_k}
# ==========================================
# 3. 모델별 임베딩/스코어 추출 함수
# ==========================================
def get_blip_scores(images_pil, texts, batch_size=16, use_itm_head=True):
assert len(images_pil) == len(texts)
n = len(images_pil)
scores = np.zeros((n, n), dtype=np.float32)
with torch.no_grad():
for i in range(n):
text = texts[i]
# 메모리 부족 방지를 위해 배치 단위 처리
for j in range(0, n, batch_size):
img_batch = images_pil[j : j+batch_size]
txt_batch = [text] * len(img_batch)
inputs = blip_processor(images=img_batch, text=txt_batch, padding=True, return_tensors='pt').to(device)
if use_itm_head:
out = blip_model(**inputs, use_itm_head=True)
itm = out.itm_score if hasattr(out, 'itm_score') and out.itm_score is not None else (out.logits if hasattr(out, 'logits') and out.logits is not None else out[0])
row_scores = itm[:, 1] if itm.dim() == 2 and itm.size(-1) == 2 else itm.view(-1)
else:
out = blip_model(**inputs, use_itm_head=False)
row_scores = out[0].view(-1)
scores[i, j : j+batch_size] = row_scores.detach().float().cpu().numpy()
return scores
def get_clip_embeddings(images_pil, texts, batch_size=32):
image_embeds_list, text_embeds_list = [], []
with torch.no_grad():
# 이미지 임베딩 추출
for s in range(0, len(images_pil), batch_size):
batch_imgs = images_pil[s:s + batch_size]
inputs = clip_processor(images=batch_imgs, return_tensors='pt', padding=True).to(device)
vision_out = clip_model.vision_model(pixel_values=inputs["pixel_values"])
img_feat = clip_model.visual_projection(vision_out.pooler_output)
image_embeds_list.append(img_feat.detach().cpu().numpy())
# 텍스트 임베딩 추출
for s in range(0, len(texts), batch_size):
batch_txt = texts[s:s + batch_size]
inputs = clip_processor(text=batch_txt, return_tensors='pt', padding=True, truncation=True).to(device)
text_out = clip_model.text_model(input_ids=inputs["input_ids"], attention_mask=inputs['attention_mask'])
text_feat = clip_model.text_projection(text_out.pooler_output)
text_embeds_list.append(text_feat.detach().cpu().numpy())
return np.concatenate(image_embeds_list, axis=0), np.concatenate(text_embeds_list, axis=0)
# ==========================================
# 4. 데이터셋 로드 및 평가 실행
# ==========================================
dataset = load_dataset('clip-benchmark/wds_flickr8k')['test']
subset = dataset.shuffle(seed=2026).select(range(100)) # 100개 샘플 추출
raw_images, raw_captions = list(subset['jpg']), list(subset['txt'])
images = [to_pil(x) for x in raw_images]
captions = [normalize_caption(x) for x in raw_captions]
# 빈 캡션 데이터 제거
keep = [i for i, c in enumerate(captions) if len(c.strip()) > 0]
images = [images[i] for i in keep]
captions = [captions[i] for i in keep]
print('Final sample size:', len(images))
# --- BLIP 성능 평가 ---
print('\n[ BLIP Retrieval Performance ]')
blip_similarity_matrix = get_blip_scores(images, captions, use_itm_head=True)
blip_result = evaluate_retrieval(blip_similarity_matrix)
for k, v in blip_result.items():
print(f'{k}: {v:.4f}')
# --- CLIP 성능 평가 ---
print('\n[ CLIP Retrieval Performance ]')
clip_image_embeds, clip_text_embeds = get_clip_embeddings(images, captions)
# CLIP 임베딩은 L2 정규화 후 내적 시 코사인 유사도가 도출됨
clip_image_embeds = l2_normalize(clip_image_embeds)
clip_text_embeds = l2_normalize(clip_text_embeds)
clip_similarity_matrix = clip_image_embeds @ clip_text_embeds.T
clip_results = evaluate_retrieval(clip_similarity_matrix)
for k, v in clip_results.items():
print(f'{k}: {v:.4f}')
4. [실습] BLIP-2를 활용한 VQA (Visual Question Answering)
BLIP-2 모델(blip2-opt-6.7b)을 이용하여 이미지를 입력받고, 사용자의 자연어 질문에 대한 답변을 생성하는 VQA 예제입니다.
- 이미지를 확인 및 로드
- 질문을 텍스트 프롬프트 형태로 입력
- 언어모델이 개입하여 자연어로 답변 생성
import requests
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
# 1. 프로세서 및 모델 로드 (이미지 전처리 + 텍스트 토크나이징)
model_id = 'Salesforce/blip2-opt-6.7b-coco'
processor = Blip2Processor.from_pretrained(model_id)
# BLIP-2 기반 이미지-조건 텍스트 생성 모델 로드
model = Blip2ForConditionalGeneration.from_pretrained(model_id, device_map='auto')
# 2. 샘플 이미지 로드
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
# 3. 프롬프트 엔지니어링 (멀티모달 모델별로 최적화된 프롬프트 형식이 존재함)
# VQA 동작을 위해 "Question: [질문] Answer: " 형태로 프롬프트 구성
question = 'Question: How many dogs are in the picture? Answer:'
# 4. 모델 입력 데이터 준비
inputs = processor(images=raw_image, text=question, return_tensors='pt').to('cuda')
# 5. 텍스트(답변) 생성
out = model.generate(
**inputs,
max_length=50, # 텍스트가 너무 짧게 끊기는 것을 방지
# do_sample=True, # 답변을 다양하게 생성하고 싶을 때 활성화
# temperature=0.7, # 모델의 창의성/무작위성 조절
)
# 6. 결과 출력 (특수 토큰 제거 후 깔끔한 문자열로 디코딩)
answer = processor.decode(out[0], skip_special_tokens=True).strip()
print(f"답변: {answer}")'개념 정리 step2 > 멀티모달(Multi-modal)' 카테고리의 다른 글
| [멀티 모달] InstructGPT부터 LLaVA까지 정리본 (0) | 2026.02.19 |
|---|---|
| [멀티 모달] DeepMind Flamingo: 언어 모델에 시각 능력을 부여하는 멀티모달 모델 (0) | 2026.02.19 |
| [비전 AI] 텍스트로 객체를 찾는 Zero-Shot Detection부터 GroundingDINO까지 (0) | 2026.02.14 |
| [머신러닝] 차원 축소 PCA, t-SNE, UMAP부터 CLIP 시각화까지 (0) | 2026.02.13 |
| [Vision-Language] CLIP 모델 핵심 정리 및 유사도 히트맵 실습 (0) | 2026.02.11 |