1. 소개
이번 프로젝트는 Pygame으로 만든 레스토랑 타이쿤 게임에 강화학습을 붙여서, 여러 알고리즘이 실제로 매장을 얼마나 잘 운영하는지 비교해 본 실험입니다.
단순히 캐릭터를 이동시키는 수준이 아니라, 에이전트가 다음과 같은 운영 의사결정을 직접 하도록 설계했습니다.
- 어디로 이동할지
- 언제 주문을 받을지
- 언제 음식을 서빙할지
- 어떤 업그레이드를 구매할지
- 특성이 등장했을 때 어떤 특성을 선택할지
즉, 이 프로젝트는 "움직이는 AI"를 만드는 것보다 "운영 전략을 학습하는 AI"를 만드는 데 더 가까웠습니다.
프로젝트의 최종 목표는 여러 강화학습 알고리즘을 같은 환경에서 학습시키고, tournament 모드에서 직접 붙여 보며 어떤 모델이 가장 좋은 성능을 내는지 확인하는 것이었습니다.
프로젝트 핵심 정보
- 장르: 레스토랑 운영 시뮬레이션
- 엔진: Python, Pygame, Gymnasium
- 행동 공간: 18개 이산 행동
- 관측 공간: 150차원 벡터
- 평가 기준: 최종
final_score
2. 강화학습 간단한 개념 정리
강화학습은 에이전트가 환경과 상호작용하면서 보상을 최대화하는 방향으로 행동을 학습하는 방법입니다.
구성 요소를 간단히 정리하면 다음과 같습니다.
상태(State)
에이전트가 현재 상황을 어떻게 보고 있는지에 해당합니다.
이 프로젝트에서는 상태에 다음과 같은 정보가 들어갑니다.
- 플레이어 위치와 방향
- 손님 상태
- 테이블 상태
- 주방 상태
- 돈, 평점, 남은 시간
- 업그레이드 상태
- 특성 선택 상태
즉, "지금 매장이 어떤 상황인지"를 150차원 벡터로 표현한 것이 상태입니다.
행동(Action)
에이전트가 할 수 있는 선택입니다.
이 프로젝트에서는 총 18개 행동이 있습니다.
- 상하좌우 이동
- 상호작용
- 대기
- 업그레이드 구매 9종
- 특성 선택 3종
이 부분이 중요한 이유는, 단순 이동뿐 아니라 경제적 선택까지 행동 공간에 들어가 있기 때문입니다.
보상(Reward)
에이전트가 좋은 행동을 했는지 알려주는 신호입니다.
예를 들면 다음과 같은 요소가 보상에 반영됩니다.
- 주문 받기
- 주방 전달
- 음식 서빙
- 손님 결제
- 손님 이탈 패널티
- 업그레이드 구매
- 평점 변화
- 최종 스코어 변화
보상 설계가 잘못되면 에이전트가 엉뚱한 행동을 반복할 수 있기 때문에, 강화학습 프로젝트에서 가장 중요한 부분 중 하나가 바로 reward shaping 입니다.
정책(Policy)
정책은 "현재 상태에서 어떤 행동을 선택할지"에 대한 기준입니다.
학습이 진행되면 에이전트는 상태를 보고 점점 더 좋은 행동을 선택하도록 정책을 업데이트합니다.
가치(Value)
어떤 상태나 행동이 장기적으로 얼마나 좋은지를 추정하는 값입니다.
당장의 작은 보상보다 미래의 큰 보상을 얻기 위한 판단에 중요합니다.
예를 들어, 지금 바로 서빙하러 가는 것보다 업그레이드를 먼저 사는 편이 장기적으로 더 많은 수익을 만들 수도 있습니다. 이런 판단을 돕는 것이 가치 추정입니다.
3. DiscreteSAC 정리
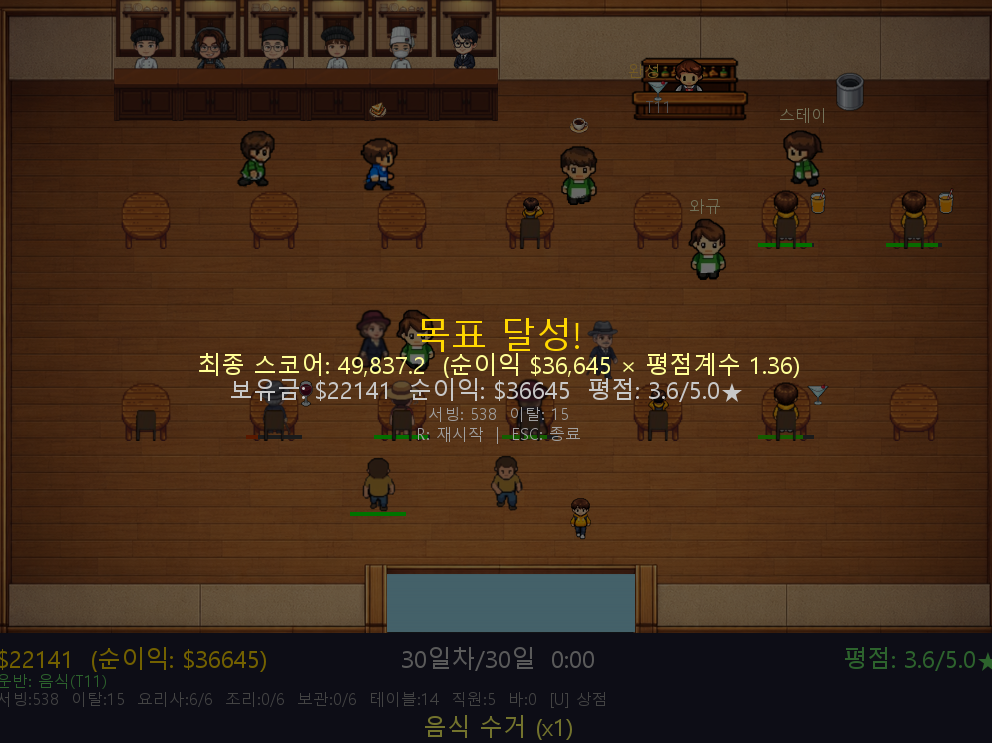
이번 프로젝트에서 가장 좋은 성능을 낸 알고리즘은 DiscreteSAC였습니다. 토너먼트 최종 결과는 다음과 같았습니다.
1위: discretesac 53,944
2위: crossplay 25,697
3위: ppo 18,132즉, 최종 결과 기준으로는 DiscreteSAC > CrossPlay > PPO 였습니다.
SAC가 무엇인가
SAC는 Soft Actor-Critic의 줄임말입니다. 기본적으로는 다음 특징을 갖습니다.
- Actor-Critic 구조를 사용함
- 확률적 정책을 사용함
- 엔트로피를 같이 최적화해서 탐험 성향을 유지함
- 학습 안정성과 성능이 좋은 편임
다만 일반적인 SAC는 연속 행동 공간에 더 자주 쓰입니다.
왜 DiscreteSAC를 썼는가
이 프로젝트의 행동 공간은 이산적입니다.
- 이동 4개
- 상호작용
- 대기
- 업그레이드 구매 9개
- 특성 선택 3개
즉, 행동이 연속값이 아니라 명확하게 분리된 선택지입니다. 그래서 이 문제에는 일반 SAC보다 DiscreteSAC가 더 잘 맞습니다.
이번 프로젝트에서 DiscreteSAC가 강했던 이유
프로젝트 기준으로 보면 DiscreteSAC가 강했던 이유는 크게 네 가지로 볼 수 있습니다.
- 이산 행동 문제와 잘 맞았다.
업그레이드 구매, 특성 선택, 상호작용은 연속 제어보다 명확한 선택 문제에 가깝습니다. DiscreteSAC는 이런 구조에 잘 맞았습니다.
- 확률적 정책이 실제 게임 플레이와 잘 맞았다.
이 프로젝트에서는 결정적 정책보다 확률적 정책이 더 자연스럽고 성능도 좋게 나오는 경우가 많았습니다. DiscreteSAC는 원래부터 확률적 정책을 잘 활용하는 구조입니다.
- 탐험과 안정성이 균형 있게 유지됐다.
단순 이동만 하는 게임이 아니라 업그레이드 타이밍, 특성 선택, 주문 처리 우선순위까지 학습해야 했기 때문에 탐험 성향이 매우 중요했습니다.
- 최종 목표와 reward shaping 정렬이 잘 맞았다.
이번 프로젝트 후반부에는 final_score_delta를 강화하고, 평가 기준도 최종 점수 중심으로 정리했습니다. 그 결과 DiscreteSAC가 실제 목표에 더 잘 맞는 방향으로 학습된 것으로 볼 수 있습니다.
4. 강화학습 개선 했던 방법
이번 프로젝트에서 가장 많은 시간을 쓴 부분은 "알고리즘을 바꾸는 것"보다 "환경과 보상을 제대로 정렬하는 것"이었습니다.
실제로 성능 개선에 영향을 준 포인트를 정리하면 다음과 같습니다.
4-1 보상 설계를 실제 목표와 맞추기
처음에는 중간 행동 보상만 따라가다 보니, 학습 보상은 높지만 실제 운영은 별로인 경우가 생길 수 있었습니다.
그래서 다음 방향으로 보상을 개선했습니다.
net_profit_delta반영rating_delta반영final_score_delta반영
특히 후반에는 final_score_delta 가중치를 정렬해서 최종 목표와 보상 방향이 어긋나지 않도록 조정했습니다.
4-2 best model 저장 기준을 mean reward에서 final score 중심으로 보기
강화학습에서는 학습 보상이 높다고 해서 실제 게임 최종 성적이 좋은 것은 아닙니다.
이번 프로젝트에서도 이 차이를 확인했고, 이후에는 최종 점수 관점이 더 중요하다는 결론을 얻었습니다.
즉, "학습이 잘 되고 있느냐"보다 "실제로 토너먼트에서 이기느냐"를 더 중요한 기준으로 보게 된 것입니다.
4-3 확률적 평가 사용
이 프로젝트에서는 결정적 정책으로 보면 오히려 이상하게 행동하는 모델이 있었습니다.
반대로 확률적 정책으로 돌렸을 때 더 자연스럽고 실제 성능도 좋았습니다.
그래서 평가와 관전에서 확률적 정책을 더 중요한 기준으로 두고 정리했습니다.
4-4 업그레이드와 특성 선택을 정책에 포함
운영 게임에서는 단순 이동보다 "언제 투자하느냐"가 더 중요할 수 있습니다.
이번 프로젝트는 업그레이드 구매와 특성 선택을 별도 스크립트가 아니라 행동 공간에 직접 넣어서, 에이전트가 운영 전략 자체를 학습하게 만들었습니다.
이 부분이 프로젝트 난이도를 크게 높였지만, 동시에 결과적으로 더 의미 있는 강화학습 문제를 만들었다고 생각합니다.
4-5 토너먼트 모드로 실제 성능 비교
하나의 알고리즘만 따로 보면 성능을 과대평가하기 쉽습니다.
이번 프로젝트에서는 최대 4개 모델을 동시에 비교할 수 있는 토너먼트 모드를 만들었고, 이를 통해 다음 장점이 생겼습니다.
- 결과를 직관적으로 확인 가능
- 최고 성능 모델을 바로 판별 가능
- 같은 환경에서 여러 알고리즘 비교 가능
결과적으로 이 모드가 최종 프로젝트 정리에서 가장 중요한 검증 도구가 되었습니다.
4-6 모델 로딩과 실험 관리 정리
실험이 많아질수록 모델 저장 형식과 로딩 규칙이 중요해집니다.
이번 프로젝트에서는 다음과 같은 점도 계속 정리했습니다.
.zip와.pt형식 구분- 알고리즘 자동 탐지
- 버전 폴더 이름으로도 학습 재개 가능하도록 런처 보완
watch,versus,tournament에서 자동 모델 탐색 지원
이런 개선은 직접적인 성능 향상이라기보다, 프로젝트 완성도를 높이는 데 중요했습니다.
5. 마무리
이번 프로젝트를 통해 느낀 점은, 강화학습 성능은 단순히 알고리즘 하나를 바꾼다고 좋아지는 것이 아니라는 점이었습니다.
실제로 중요한 것은 다음 세 가지였습니다.
- 문제를 어떤 상태와 행동으로 정의했는가
- 보상을 최종 목표와 얼마나 잘 맞췄는가
- 평가를 실제 사용 방식과 비슷하게 했는가
최종적으로는 DiscreteSAC가 가장 좋은 성능을 보였고, 프로젝트 차원에서는 운영형 시뮬레이션 문제에서 강화학습을 어떻게 적용하고 검증할 수 있는지 정리할 수 있었습니다.
앞으로 더 확장한다면 다음 방향도 가능할 것 같습니다.
- 더 긴 기간 학습
- 맵 구조 다양화
- 손님 유형 다양화
- 멀티에이전트 협업 강화
- CrossPlay 자동 리그 시스템 고도화
6. GitHub 링크
GitHub - EPOCH-X/RL-Tycoon-Agent: 타이쿤 게임의 운영 및 수익 최적화를 목표로 하는 강화학습 에이전트
타이쿤 게임의 운영 및 수익 최적화를 목표로 하는 강화학습 에이전트 실험 프로젝트. 상태(State)와 보상(Reward) 설계에 따른 에이전트의 행동 변화 분석. - EPOCH-X/RL-Tycoon-Agent
github.com

'4. [팀] 프로젝트 및 공모전 > 4-3 RL-Tycoon-Agent' 카테고리의 다른 글
| [개인 공부] RL-Tycoon-Agent "강화학습" 개인 공부 기록(2) (0) | 2026.03.08 |
|---|---|
| [개인 공부] RL-Tycoon-Agent "강화학습" 개인 공부 기록(1) (0) | 2026.03.06 |