주제: 레스토랑 경영 타이쿤 게임에 강화학습(PPO)을 적용한 에이전트 개발, 디버깅 및 튜닝 기록
환경: Python 3.12 / Pygame 2.6 / Gymnasium / Stable-Baselines3 / PyTorch (CUDA RTX 4070 Ti)
저는 알고리즘 별 로직을 나눠서 테스트 하는 중입니다. 참고 바랍니다.
1. 프로젝트 개요
| 항목 | 상세 내용 |
| 게임 환경 | 16×10 그리드 2D 레스토랑 타이쿤 |
| 에이전트 목표 | 서빙, 주방 관리, 업그레이드를 자율 수행하며 30일 경영 |
| 에피소드 길이 | 9,000 스텝 (30일 × 60초/일 ÷ 0.2초/스텝) |
| 환경 래퍼 | Gymnasium (연속 행동: 이동 + 자동 인터랙트) |
| 알고리즘 | PPO (MlpPolicy, [256, 256], tanh) |
| 학습 파라미터 | n_envs=8, n_steps=2048, batch=128, lr=3e-4, ent_coef=0.01 |
게임 상태 흐름(State Flow):
입장 → 착석 → 주문 접수 → 주방 전달 → 조리 대기 → 음식 수거 → 서빙 → 결제 → 평점 반영
(최종 점수: net_profit × (1 + rating_stars / 10))
2. 초기 구조 — 학습 실패 원인 분석
초기 에이전트는 리워드가 0 근처에서 머물며 유의미한 행동을 학습하지 못했습니다. 분석 결과 아래 5가지 주요 문제가 중첩되어 있었습니다.
- A3C 연산 그래프 그래디언트 누락
- 알고리즘 간 모델 로딩 메타데이터 불일치
- PPO Reward shaping의 감가율(γ) 발산
- 이산 행동(Discrete) 상호작용 타이밍 제어의 복잡도
- 퇴장 고객에 의한 환경 상태(State) 오염
2-1 버그 #1: A3C backward() 에러
증상:
- RuntimeError: Trying to backward through the graph a second time 발생.
원인:
- Actor loss와 Critic loss 계산 시 동일 연산 그래프에 backward()를 중복 호출함.
해결:
- Actor loss와 Critic loss를 total_loss로 합산하여 backward() 단일 호출로 수정.
- 단일 Optimizer로 통합 및 신경망 가중치 Orthogonal 초기화 적용.
2-2 버그 #2: 멀티 알고리즘 로딩 크래시
증상:
- 저장된 모델(SAC, A3C)을 평가 모드(watch)로 로드할 때 KeyError 및 크래시 발생.
원인:
- 알고리즘별 요구하는 Action/Observation Space가 현재 환경과 불일치.
해결:
- 모델 저장 시 메타데이터(algorithm, obs_shape, act_shape) 기록.
- 로딩 시 메타데이터 검증을 거쳐 호환되는 환경 래퍼로 동적 재생성.
2-3 버그 #3: PPO가 정지하는 문제
증상:
- 에이전트가 이동을 멈추고 제자리에 대기하여 Idle 패널티만 누적. 탐색(Entropy)은 정상이나 최적화 실패.
원인 1: Reward Shaping의 감가율 누수
- Dense reward shaping 공식에서 환경 보상 감가율이 아닌 PPO 내부 감가율(gamma=0.99)을 사용하여 에피소드 후반부 잠재 함수가 발산함.
해결 1:
- $\gamma=1.0$ 적용 (최적 정책 보존), Scale 3.0, Cap ±1.0 설정.
원인 2: 인터랙트 타이밍 학습의 한계
- 6개의 이산 행동(상/하/좌/우/대기/인터랙트)으로 설계되어, 특정 좌표 도달과 인터랙트 실행을 동시에 수행하는 정책을 찾지 못함.
해결 2:
- 행동 공간을 연속 벡터(dx, dy) 이동으로 변경. 목표 범위 도달 시 자동 상호작용되도록 래퍼 수정.
2-4 버그 #4: 인간 vs 에이전트 상호작용 격차
증상:
에이전트 이동 속도는 인간 플레이어와 같으나, 상호작용 빈도와 서빙 처리량이 절반 이하로 저하됨.
원인:
인간 모드는 60fps로 충돌 및 상호작용을 체크하지만, 에이전트는 0.2초(1스텝) 간격으로만 명령을 전달하여 타겟을 스쳐 지나가는 현상 발생. 타겟 방향을 바라보지 않는 방향 전환(Facing) 누락.
해결:
- _try_auto_interact(): 스텝마다 최적 대상 자동 탐색 및 인터랙트 강제 실행.
- _get_primary_target_point(): 상태 기반 최우선 목표 좌표 계산 및 해당 방향으로 자동 몸체 회전(_auto_face_nearest()).
2-5 버그 #5: Orphan Food 누적
증상:
대기 시간 초과로 이탈한 고객의 음식이 주방/바/플레이어 손에 누적되어 게임 상태 공간(State Space) 오염.
원인:
고객 상태가 LEAVING_ANGRY로 변경될 때 연결된 조리/대기 인스턴스를 소멸시키는 로직 부재.
해결:
- remove_for_table(table_id) 메서드를 각 스테이션에 추가하여 퇴장 시 호출.
- 플레이어가 고아 음식을 소지한 경우 최우선으로 쓰레기통으로 이동하도록 지시. 해당 음식 폐기 시 리워드(+0.5) 부여.
3. 개선 사항
3-1 개선 #1: 최종 점수 공식 수정
기존: final_score = net_profit × (rating_stars / 10)
문제: 평점이 낮을 경우 이익이 기하급수적으로 삭감되어 에이전트가 평점을 무시하는 방향으로 학습.
수정: final_score = net_profit × (1.0 + rating_stars / 10.0)
평점을 순이익 보존이 아닌 '추가 배율 보너스(최대 1.5배)'로 변경.
3-2 개선 #2: 전략적 업그레이드 우선순위
무작위 또는 저비용 순 업그레이드 구매로 인한 자원 낭비를 막기 위해, 휴리스틱 기반 ROI 우선순위를 적용하여 에이전트의 정책 탐색 공간을 축소했습니다.
_UPGRADE_PRIORITY = {
"hire_waiter": 10,
"hire_chef": 9,
"speed_shoes": 8,
"hire_bartender": 7,
"cook_speed": 6,
"kitchen_expand": 5,
"buy_table": 4,
"hire_delivery": 3,
"carry_capacity": 2,
"attract_customer": 1,
}
3-3 개선 #3: 가치 점수 기반 특성(Trait) 선택
특성 선택 시 고정 인덱스(1번)를 선택하던 방식에서, 특성별 가중치 테이블을 기반으로 자동 선택하도록 수정했습니다.
(최우선 특성: 서빙 대기 시간 증가, 서빙 속도 보너스, 메뉴 가격 보너스 순)
3-4 종업원 이동 좌표 계산 오류
증상: NPC 종업원이 목표 지점에 정차하지 못하고 벽을 뚫거나 제자리에서 진동함.
원인: 거리 계산 시 타일 중심점과 엔티티의 좌상단 좌표를 비교하여 히트박스 오프셋 지속 발생.
해결: 엔티티 중심(cx, cy) 좌표계로 통일하고, 도착 판정 반경(Arrive distance)을 타일 크기의 60%로 상향 조정.
4. 보상 함수(Reward Function) 구조
행동 궤적을 유도하는 최종 보상 파라미터입니다. 자원 처리의 핵심 병목인 '음식 서빙'에 최고 가중치를 할당했습니다.
| 트리거 이벤트 | 리워드 가중치 | 설명 |
| take_order | +8.0 | 테이블 주문 접수 |
| submit_kitchen | +5.0 | 주방에 주문서 전달 |
| pickup_food | +5.0 | 조리된 음식 수거 |
| serve_food | +15.0 | 음식 서빙 (핵심 목표) |
| pickup_drink | +3.0 | 음료 수거 |
| serve_drink | +8.0 | 음료 서빙 |
| customer_payment | +1.0 | 결제 완료 (× 결제 금액 보정) |
| lost_customer | -15.0 | 손님 이탈 (핵심 방어 목표) |
| wrong_table | -2.0 | 잘못된 테이블에 서빙 시도 |
| trash | -1.0 | 멀쩡한 음식 폐기 |
| trash_orphan | +0.5 | 고아 음식 올바르게 폐기 |
| blocked_move | -0.1 | 벽 충돌 패널티 |
| idle_penalty | -0.3 | 제자리 대기 패널티 |
| time_penalty | -0.02 | 매 스텝 시간 압박 |
| buy_upgrade | +2.0 | 인프라 업그레이드 |
| food_unlock | +0.3 | 신메뉴 해금 (× 단가 보정) |
| win | +200.0 | 30일(1 에피소드) 완주 보너스 |
거리 기반 Shaping Reward 공식:
(목표 지점과의 정규화된 거리를 $\phi(s)$로 사용)
5. 학습 결과 타임라인
PPO v3 (Auto-interact + 고아 음식 처리 적용)
- 총 학습: 10M 스텝 (약 2시간)
- 최고 리워드: 19,003.3
- 최종 Mean Reward: 13,531 (서빙 평균 189회, 순이익 $4,961)
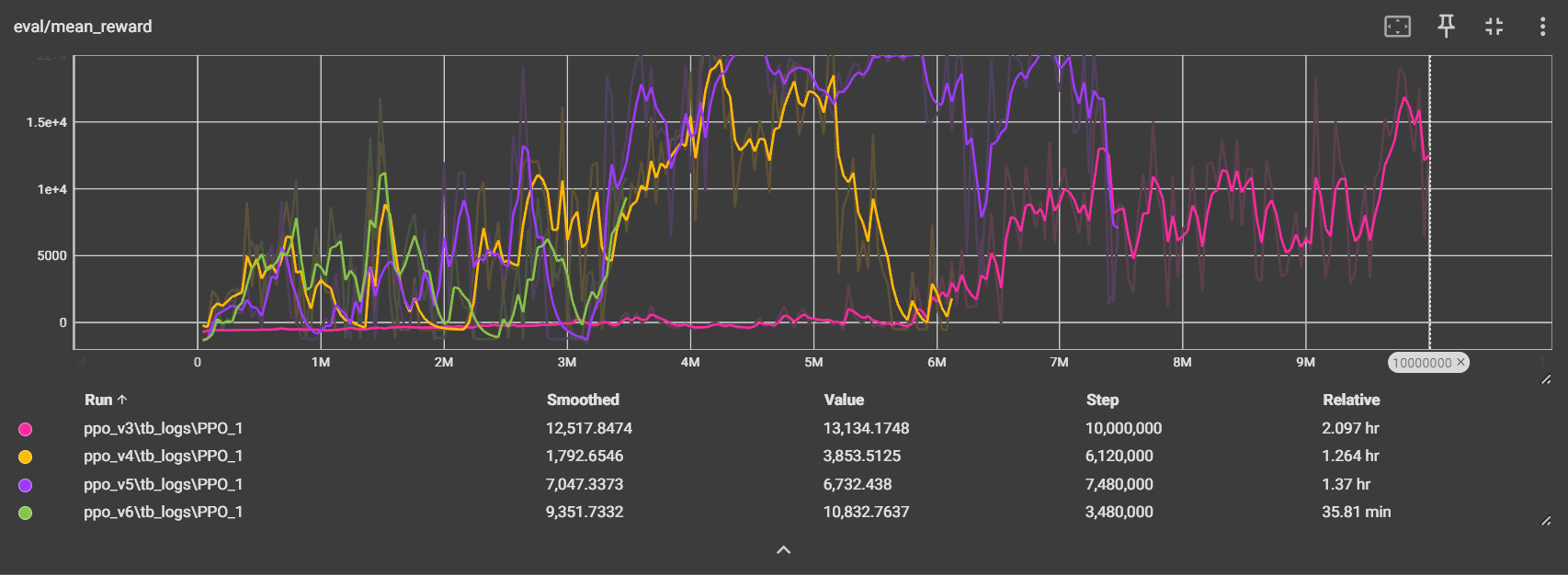
그래프를 보면 흔들리다가 상승곡선을 그리는 부분은 탐색 성공을 뜻하는 거 같다.
분홍색 외의 그래프는 다른 방법으로 테스트를 진행중이다.
6. 아키텍처 및 설정 구조
컴포넌트 의존성:
main.py
├─ core/shop.py (게임 엔진, 상태 관리)
│ ├── player.py, customer.py (엔티티, 상태머신)
│ └── employee.py, station.py (NPC/스테이션 로직)
├─ ai/gym_env.py (강화학습 래퍼, 보상/관측공간 정의)
├─ ai/train.py (SB3 학습 루프 제어)
└─ rendering/renderer.py (Pygame UI 분리)
설정 파일 분리:
모델 하이퍼파라미터와 게임 내 정적 데이터(메뉴 단가, 업그레이드 비용, 특성 스탯 등)를 분리하여 config/*.json 형태로 주입하여 환경 수정의 유연성을 확보했습니다.
'4. [팀] 프로젝트 및 공모전 > 4-3 RL-Tycoon-Agent' 카테고리의 다른 글
| [강화 학습] RL-Tycoon-Agent 프로젝트 정리 (0) | 2026.03.22 |
|---|---|
| [개인 공부] RL-Tycoon-Agent "강화학습" 개인 공부 기록(2) (0) | 2026.03.08 |