1. 제안 배경: 기존 트랜스포머의 한계
Swin Transformer는 기존 자연어 처리(NLP)에 맞춰진 트랜스포머를 이미지 처리(비전)에 적용할 때 발생하는 두 가지 근본적인 문제를 해결하기 위해 등장했습니다.
- 객체 크기의 변동성: 텍스트의 단어와 달리, 이미지 속 시각적 개체들은 크기가 매우 다양하게 나타납니다.
- 과도한 연산량 (이차 복잡도): 이미지는 텍스트에 비해 해상도(픽셀 수)가 훨씬 높습니다. 픽셀 단위로 세밀한 예측이 필요한 비전 작업에서 기존 트랜스포머의 전역 자기-어텐션을 그대로 사용하면, 연산 복잡도가 픽셀 수의 제곱에 비례하여 감당할 수 없게 됩니다.
2. 핵심 방법론 (Core Methodology)
이러한 문제를 해결하기 위해 고안된 Swin Transformer의 아키텍처는 크게 세 가지 구조적 특징을 가집니다.
2-1 계층적 아키텍처 구성 (Overall Architecture)
이미지를 작은 패치로 나누고, 네트워크가 깊어짐에 따라 패치를 병합해 해상도를 줄여나가는 방식입니다.
- 초기 처리: 입력된 이미지를 겹치지 않는 패치로 분할합니다. 4x4 크기의 패치를 사용하면 각 패치의 특징 차원은 $4 \times 4 \times 3 = 48$이 됩니다. 여기에 선형 임베딩을 적용해 차원을 $C$로 맞추고 첫 번째 블록(Stage 1)을 통과시킵니다.
- 패치 병합 (Patch Merging): 네트워크가 깊어질 때마다 2x2 이웃 패치 그룹을 하나로 묶습니다. 해상도는 가로세로 각각 절반(전체의 1/4)으로 줄어들고, 출력 차원은 2배($2C$)로 늘어납니다.
- 의의: 이 과정을 Stage 2, 3, 4로 반복하면서 기존의 VGG나 ResNet 같은 합성곱 신경망(CNN)과 동일한 계층적 특징 맵을 생성합니다. 덕분에 기존 비전 모델의 기본 뼈대로 쉽게 교체하여 사용할 수 있습니다.
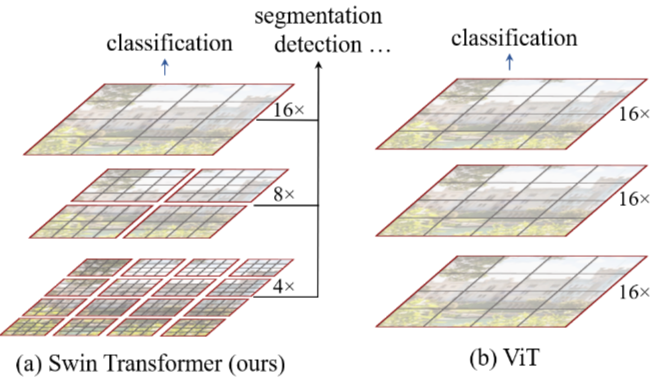
이 이미지는 Swin Transformer와 기존 Vision Transformer (ViT)의 특징 맵 생성 방식을 시각적으로 비교하여 보여줍니다.
(a) Swin Transformer (ours):
- Swin Transformer는 계층적(hierarchical) 특징 맵을 생성합니다. 이는 작은 크기의 패치(patches)에서 시작하여 네트워크가 깊어질수록 인접한 패치를 병합하면서 특징 맵의 해상도를 점진적으로 낮추는 방식입니다.
- 그림에서 볼 수 있듯이, 가장 위에는 높은 해상도의 특징 맵이 있고, 아래로 내려갈수록 해상도가 1/2, 1/4로 줄어들어 더 넓은 영역의 특징을 통합합니다 (예: 4x, 8x, 16x 다운샘플링).
- 이러한 계층적 구조는 객체 탐지(detection)나 의미론적 분할(segmentation)과 같이 다양한 스케일의 특징을 이해해야 하는 조밀한 예측(dense prediction) 작업에 매우 유용합니다.
- 또한, 각 단계별로 다른 해상도의 특징 맵을 제공하여 다양한 규모의 시각적 요소를 모델링하는 데 유연성을 제공합니다.
(b) ViT (Vision Transformer):
- 기존 ViT는 입력 이미지를 고정된 크기의 패치로 나누어 처리하며, 이러한 패치 토큰들은 네트워크 전체에 걸쳐 동일한 해상도의 특징 맵을 유지합니다.
- 그림에서 볼 수 있듯이, ViT는 초기 단계부터 최종 단계까지 동일한 해상도의 특징 맵을 유지하며, 이는 주로 이미지 분류(classification)와 같은 작업에 초점을 맞춘 설계입니다.
- 조밀한 예측 작업에 사용하기 위해서는 일반적으로 추가적인 업샘플링(upsampling) 또는 디컨볼루션(deconvolution)과 같은 과정이 필요하며, 이는 ViT의 설계 목적과는 다소 차이가 있습니다.
핵심 차이점:
Swin Transformer는 계층적 특징 맵을 생성하여 다양한 스케일의 시각적 정보를 효과적으로 모델링합니다.
ViT는 단일 해상도의 특징 맵을 생성하며, 이는 주로 이미지 분류와 같은 특정 작업에 적합합니다.
이러한 계층적 구조의 차이는 Swin Transformer가 CNN과 유사하게 다양한 컴퓨터 비전 작업에서 범용적인 백본으로 활용될 수 있게 하는 중요한 이유 중 하나입니다.
2-2 윈도우 기반 자기-어텐션 (W-MSA & SW-MSA)
연산량을 획기적으로 줄이면서도 모델의 성능을 끌어올린 가장 핵심적인 기술입니다.
- W-MSA (중첩되지 않는 윈도우 내 연산): 전체 이미지가 아닌, 이미지를 고르게 분할한 로컬 윈도우(예: $M \times M$ 패치) 안에서만 어텐션을 계산합니다. 전체 패치 수가 $hw$일 때 계산 복잡도를 비교하면 다음과 같습니다.
- 전역 MSA: $\Omega(\text{MSA}) = 4hwC^2 + 2(hw)^2C$ (패치 수의 제곱에 비례)
- 윈도우 기반 MSA: $\Omega(\text{W-MSA}) = 4hwC^2 + 2M^2hwC$ (패치 수에 선형적으로 비례)
- 즉, $M$을 고정하면 연산량이 이미지 크기에 선형적으로만 증가하여 매우 효율적입니다.
- SW-MSA (이동된 윈도우 파티셔닝):
- 이전 레이어에서 기준 윈도우를 나누었다면, 다음 레이어에서는 윈도우를 $(\lfloor M/2 \rfloor, \lfloor M/2 \rfloor)$ 픽셀만큼 이동시켜 새롭게 구성합니다.
- 이 과정을 통해 이전 레이어에서 서로 다른 윈도우에 속했던 패치들이 연결되며 전체적인 문맥을 파악하게 됩니다.
- W-MSA만 쓰면 윈도우들 사이의 정보 교환이 단절됩니다. 이를 극복하기 위해 연속된 블록에서 윈도우의 기준점을 이동(Shift)시킵니다.
- 효율적인 배치 계산 (Cyclic-shifting):
- 윈도우를 이동시키면 모서리 부분에 작은 자투리 윈도우들이 생겨 연산이 비효율적이 됩니다. 빈 공간을 채우는 패딩 대신, 남는 영역을 왼쪽 위로 순환 이동(Cyclic-shifting)시키고 연산이 섞이지 않도록 마스킹(Masking) 처리를 하여 윈도우 개수와 연산 효율을 원래대로 유지합니다.

- 좌측 (Layer 1): 첫 번째 레이어에서는 이미지가 네 개의 큰 사각형(로컬 윈도우)으로 나뉩니다. 각 큰 사각형 안에는 더 작은 격자무늬들이 보이는데, 이것들은 "패치(patch)"를 나타냅니다. 이 레이어에서는 각 로컬 윈도우 내부에서만 셀프-어텐션(self-attention)이 계산됩니다.
- 우측 (Layer l+1): 다음 레이어에서는 윈도우의 분할 방식이 이동(shift)됩니다. 이전 레이어의 윈도우 경계를 넘어서 새로운 모양의 윈도우들이 생성됩니다. 예를 들어, 이전 레이어에서 상단 두 개의 윈도우가 있던 자리에, 이제는 더 작고 긴 형태의 윈도우들이 배치됩니다. 이렇게 윈도우를 이동시킴으로써, 이전 레이어의 서로 다른 윈도우에 속해 있던 패치들 간의 연결성이 생기게 됩니다.
- 범례:
테두리가 있는 큰 사각형은 셀프-어텐션을 수행하는 "로컬 윈도우"를 의미합니다.
작은 회색 사각형은 이미지를 구성하는 기본 단위인 "패치"를 의미합니다.
이 이동된 윈도우 방식은 다음과 같은 장점을 가집니다.
- 효율성: 셀프-어텐션 계산을 로컬 윈도우로 제한함으로써, 이미지 크기에 대한 계산 복잡도를 선형적으로 유지할 수 있습니다. 기존 비전 트랜스포머(Vision Transformer)의 경우, 이미지 전체에 대해 셀프-어텐션을 계산하기 때문에 계산량이 이미지 크기의 제곱에 비례하여 급증하는 문제가 있었습니다.
- 모델링 능력 향상: 윈도우를 이동시킴으로써 이전 레이어에서 서로 연결되지 않았던 윈도우 간의 정보 교환이 가능해집니다. 이는 모델이 이미지의 더 넓은 영역에 걸친 관계를 학습하는 데 도움을 줍니다.
이러한 이동된 윈도우 메커니즘은 Swin Transformer가 이미지 분류뿐만 아니라 객체 탐지, 의미론적 분할과 같은 다양한 컴퓨터 비전 작업에서 뛰어난 성능을 발휘하게 하는 핵심 요소입니다.
2-3 상대적 위치 편향 (Relative Position Bias)
어텐션 점수를 계산할 때, 각 헤드에 상대적인 위치 정보를 더해줍니다.
절대적인 위치 좌표를 더하는 것보다, 패치 간의 '상대적 거리'를 반영하는 편향 값($B$)을 더했을 때 객체 탐지나 분할처럼 위치와 경계가 중요한 세밀한 작업에서 성능이 훨씬 크게 향상됨을 확인했습니다.
2-4 Swin Transformer의 전체적인 아키텍처 (이미지 설명)

전체 아키텍처 (a)
- 입력 (Images): $H \times W$ 크기의 RGB 이미지가 입력으로 들어옵니다.
- Patch Partition: 이미지를 $4 \times 4$ 크기의 패치로 나눕니다. 초기 특징 차원은 48 ($4 \times 4$ 픽셀 $\times$ 3 채널)이 됩니다.
- Linear Embedding: 패치 차원을 $C$ 차원으로 선형적으로 임베딩합니다.
- Stage 1: 이 단계는 $H/4 \times W/4$ 해상도와 $C$ 차원을 가지며, Swin Transformer 블록이 2번 반복됩니다.
- Patch Merging: 각 단계마다 특징 맵의 해상도를 절반으로 줄이고 채널 차원을 두 배로 늘립니다. 예를 들어, Stage 1에서 Stage 2로 넘어갈 때 해상도는 $H/8 \times W/8$이 되고 차원은 $2C$가 됩니다.
- Stage 2, 3, 4: 각 단계는 Patch Merging 레이어와 Swin Transformer 블록으로 구성됩니다. Stage 2는 2번, Stage 3는 6번, Stage 4는 2번의 Swin Transformer 블록을 포함합니다. 각 단계가 진행될수록 해상도는 감소하고 채널 차원은 증가합니다 (Stage 2: $H/8 \times W/8 \times 2C$, Stage 3: $H/16 \times W/16 \times 4C$, Stage 4: $H/32 \times W/32 \times 8C$).
- 계층적 표현: 이러한 단계적인 구조를 통해 Swin Transformer는 다양한 스케일의 특징을 추출하는 계층적인 특징 맵을 생성합니다.
두 개의 연속적인 Swin Transformer 블록 (b)
- W-MSA (Window Multi-head Self-Attention): 각 윈도우 내에서 셀프-어텐션을 계산합니다.
- SW-MSA (Shifted Window Multi-head Self-Attention): 다음 블록에서 윈도우 파티션을 이동시켜 이전 윈도우 간의 연결성을 생성합니다.
- LN (Layer Normalization): 각 MSA 및 MLP 모듈 앞에 Layer Normalization을 적용합니다.
- MLP (Multi-Layer Perceptron): 두 개의 선형 계층과 GELU 활성화 함수로 구성된 MLP 모듈입니다.
- Residual Connection: 각 W-MSA/SW-MSA 모듈과 MLP 모듈 후에 잔차 연결(residual connection)이 적용됩니다.
- 수식 기호: $z^l$은 블록 $l$의 출력이고, $\hat{z}^l$은 W-MSA 또는 SW-MSA 모듈의 출력입니다. $z^{l-1}$은 이전 블록의 출력이 입력으로 사용됨을 나타냅니다.
요약
이 아키텍처는 기존 Vision Transformer(ViT)의 글로벌 셀프-어텐션이 가지는 이미지 크기에 대한 2차 계산 복잡도 문제를 해결하고, 계층적 특징 표현을 생성함으로써 다양한 비전 작업에 대한 일반적인 목적의 백본으로 사용될 수 있게 합니다.
3. 모델 변형 및 실험 결과
아키텍처 변형:
모델의 크기와 연산량에 따라 Tiny(Swin-T), Small(Swin-S), Base(Swin-B), Large(Swin-L) 4가지 버전을 제공합니다. (기본 윈도우 크기 $M=7$, 쿼리 차원 $d=32$ 설정)
주요 실험 성과:
- 분류, 탐지, 분할 올킬: ImageNet-1K(분류), COCO(객체 탐지), ADE20K(시맨틱 분할) 등 주요 벤치마크에서 기존의 최첨단 CNN 모델과 트랜스포머 모델들을 모두 압도적인 차이로 능가했습니다. 특히 객체 탐지에서는 기존 최고 기록을 박스 AP 기준 2.7, 마스크 AP 기준 2.6이나 끌어올렸습니다.
- 제거 연구(Ablation Study): 윈도우를 이동시키는 방식(Shifted Windows)과 상대적 위치 편향 기법을 뺐을 때 성능이 급격히 하락하는 것을 확인하여, 이 두 가지 아이디어가 성공의 핵심 열쇠임을 증명했습니다.
결론 (Conclusion)
Swin Transformer는 계층적 특징 표현과 이미지 크기에 대한 선형 계산 복잡도를 가진 새로운 Vision Transformer입니다. 이 모델은 COCO 객체 탐지 및 ADE20K 시맨틱 분할에서 최첨단 성능을 달성하며 기존 최고 방법론을 크게 능가했습니다.
Swin Transformer의 다양한 비전 문제에서의 강력한 성능은 비전 및 언어 신호의 통합 모델링을 촉진할 것으로 기대됩니다. 핵심 요소인 Shifted Window 기반 자기-어텐션은 비전 문제에서 효과적이고 효율적임이 입증되었으며, 향후 자연어 처리 분야에서의 적용 가능성도 탐구될 수 있습니다.
'1. AI 논문 + 모델 분석 > AI 논문 분석' 카테고리의 다른 글
| [논문 리뷰] Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection (0) | 2026.02.25 |
|---|---|
| [논문 리뷰] DETR: 객체 검출(Object Detection)의 End-to-End 파이프라인 (0) | 2026.02.22 |
| [논문 구현] 멀티모달 병목 트랜스포머(MBT) PyTorch 구현 및 RAVDESS 감정 인식 테스트 (0) | 2026.02.16 |
| [논문 리뷰] Multimodal Bottleneck Transformer (MBT) (0) | 2026.02.15 |
| [논문 리뷰] CLIP: 텍스트로 이미지를 이해하는 비전 모델 (OpenAI) (0) | 2026.02.12 |