안녕하세요!
오늘 리뷰할 논문은 인간의 인지 방식에서 영감을 받아 비디오 분류(Video Classification)를 위한 새로운 멀티모달 융합 방식을 제안한 Multimodal Bottleneck Transformer (MBT) 입니다.
처음 멀티모달 논문을 접할 때 가장 헷갈리는 부분 중 하나가 바로 "그래서 이미지랑 소리를 언제, 어떻게 합친다는 거지?"라는 점입니다. 이 논문은 그 질문에 대해 'Bottleneck(병목)'이라는 아주 직관적이고 효율적인 해답을 제시합니다.
https://arxiv.org/abs/2107.00135
Attention Bottlenecks for Multimodal Fusion
Humans perceive the world by concurrently processing and fusing high-dimensional inputs from multiple modalities such as vision and audio. Machine perception models, in stark contrast, are typically modality-specific and optimised for unimodal benchmarks,
arxiv.org
1. 들어가며: 멀티모달 학습의 딜레마
비디오 데이터는 기본적으로 시각(RGB 프레임)과 청각(오디오 스펙트로그램)이라는 두 가지 이상의 모달리티(Modality)로 구성됩니다. 우리가 영상을 볼 때 눈과 귀를 동시에 사용하듯, 인공지능도 이 두 가지 정보를 잘 융합해야 비디오의 맥락을 정확히 이해할 수 있습니다.
기존의 머신러닝 모델들은 주로 이 정보를 합치는 시점에 따라 두 가지로 나뉘었습니다.
Early-fusion:
- 입력 단계에서 두 데이터를 냅다 합쳐버립니다. 정보 손실은 적지만, 서로 완전히 다른 특성을 가진 두 데이터(예: 픽셀 값과 주파수 값)를 처음부터 억지로 섞다 보니 모델이 학습하기 매우 어렵고 연산량이 폭발적으로 증가합니다.
Late-fusion:
- 각자(Vision, Audio) 따로따로 끝까지 학습을 진행한 뒤, 마지막 예측 단계(최종 로짓이나 확률 값)에서만 슬쩍 결과를 합칩니다. 학습은 쉽고 빠르지만, 시각과 청각 정보가 서로 유기적으로 상호작용할 기회를 잃어버립니다. (예: "저 입술 움직임(시각)이 이 목소리(청각)를 만드는구나"라는 맥락을 놓침)
본 논문은 이 극단적인 두 방식 사이에서 "중간 단계에서, 그것도 꼭 필요한 정보만 아주 압축해서 교환하자"는 아이디어를 Transformer 구조를 통해 구현해 냅니다.
2. MBT의 핵심: 'Fusion Bottleneck' 메커니즘
이 논문의 가장 큰 기여는 '병목(Bottleneck)' 토큰의 도입입니다.
Transformer의 핵심인 Self-Attention은 모든 토큰이 다른 모든 토큰을 바라보며 연산합니다($\mathcal{O}(N^2)$의 복잡도). 만약 비디오 패치 토큰 수천 개와 오디오 패치 토큰 수천 개를 그냥 한 공간에 넣고 Attention을 돌린다면(Vanilla self-attention), 연산량이 감당이 안 될 뿐더러, 시각과 청각 사이의 노이즈까지 서로에게 전달될 수 있습니다.
해결책: 소수의 '대표(Bottleneck)'만 회의실에 보낸다.
MBT는 시각 토큰들과 청각 토큰들이 서로 직접 소통하는 것을 차단합니다. 대신, $B$개라는 아주 적은 수의 '병목 토큰(Bottleneck Tokens)'을 새로 만듭니다.
- 시각 토큰들은 시각 정보끼리 교류하되, 모아진 핵심 정보를 병목 토큰에게 전달합니다.
- 청각 토큰들도 마찬가지로 핵심 정보를 병목 토큰에게 전달합니다.
- 이 병목 토큰들이 다른 모달리티로 넘어가서 자신이 요약해 온 정보를 전달해 줍니다.
결과적으로 엄청난 연산량 감소는 물론, 모델이 각 모달리티에서 가장 관련성 높고 필수적인 정보만 응축하여 전달하도록 강제하는 효과(Regularization)를 얻게 됩니다.
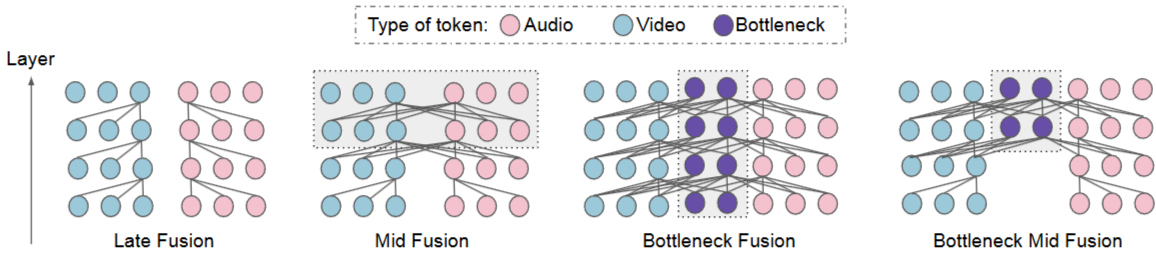
이 그림은 오디오와 비디오라는 두 가지 모달리티의 정보를 융합하는 네 가지 다른 전략을 시각적으로 보여줍니다. 각 세로 열은 특정 융합 전략을 나타내며, 위에서 아래로 갈수록 레이어가 깊어짐을 나타냅니다. 원은 "토큰"을 나타내며, 색깔은 토큰의 모달리티를 나타냅니다: 분홍색은 오디오, 파란색은 비디오, 보라색은 병목(bottleneck) 토큰입니다.
Late Fusion (늦은 융합):
가장 왼쪽에 있는 열입니다. 이 전략에서는 오디오와 비디오 토큰들이 서로 독립적으로 처리됩니다. 각 모달리티의 정보는 모델의 깊은 레이어까지 교환되지 않습니다. "Late Fusion"이라는 이름에서 알 수 있듯이, 모달리티 간의 정보 융합은 모델의 마지막 단계, 즉 분류기 직전에 이루어집니다. 각 모달리티는 자체적인 잠재 표현을 학습하며, 이들이 마지막에 결합됩니다.
Mid Fusion (중간 융합):
두 번째 열입니다. 이 전략에서는 모델의 초기 레이어에서는 각 모달리티가 독립적으로 처리됩니다 (예: 분홍색 및 파란색 원들). 어느 시점(보통 중간 레이어)부터 오디오와 비디오 토큰들 사이에 교차-모달 어텐션이 가능해집니다. 그림에서 회색 음영 영역은 이 교차-모달 상호작용이 발생하는 레이어를 나타냅니다. 이것은 "Late Fusion"보다 더 이른 시점에 정보 교환이 이루어지지만, "Early Fusion"(모든 레이어에서 교차-모달 상호작용 허용)보다는 늦은 시점에 이루어지는 절충안입니다.
Bottleneck Fusion (병목 융합):
세 번째 열입니다. 이 전략의 핵심은 "병목(bottleneck)" 토큰(보라색 원)의 도입입니다. 각 레이어에서 오디오와 비디오 토큰들은 직접적으로 서로에게 어텐션하는 대신, 소수의 병목 토큰을 통해서만 정보를 교환합니다. 이는 마치 정보가 좁은 병목을 통과하는 것처럼, 각 모달리티에서 중요한 정보만 압축하여 공유하도록 강제합니다. 이를 통해 계산 비용을 절감하면서도 효율적인 융합을 목표로 합니다.
Bottleneck Mid Fusion (병목 중간 융합):
가장 오른쪽에 있는 열입니다. 이 전략은 "Mid Fusion"과 "Bottleneck Fusion"을 결합한 것입니다. 모델의 초기 레이어에서는 각 모달리티가 독립적으로 처리됩니다. 중간 레이어부터 병목 토큰(보라색 원)을 통해 오디오와 비디오 토큰 간의 정보 교환이 이루어집니다. 이것은 두 전략의 장점을 결합하여, 중간 시점에 효율적인 병목 메커니즘을 통해 융합을 수행합니다.
이 그림은 논문에서 제안하는 '어텐션 병목' 개념을 시각화하고, 이를 다른 융합 전략과 비교하여 보여줍니다. 특히 "Bottleneck Mid Fusion"이 계산 효율성과 성능 면에서 장점을 가질 수 있음을 시사합니다.
3. 단계별 작동 원리 (알고리즘 분해)
논문에 제시된 수식과 함께 데이터가 어떻게 흘러가는지 구체적으로 살펴보겠습니다.
3-1 입력 토큰화 (Input Tokenization)
Vision Transformer(ViT)나 Audio Spectrogram Transformer(AST)의 방식을 그대로 따릅니다.
- 비디오 프레임과 오디오 스펙트로그램을 각각 겹치지 않는 2D 패치로 잘게 쪼갭니다.
- 이 패치들을 선형 프로젝션 행렬 $E$를 통과시켜 1D 벡터인 $z_i \in \mathbb{R}^d$ 로 변환(Embedding)합니다.
여기에 분류를 담당할 특별한 $\text{CLS}$ 토큰과 위치 정보를 담은 위치 임베딩 $p$를 더해줍니다.
3-2 Transformer 레이어 통과
생성된 토큰들은 멀티헤드 셀프 어텐션(MSA)과 다층 퍼셉트론(MLP)으로 구성된 정통 Transformer 인코더를 통과합니다.
3-3 Attention Bottlenecks를 통한 융합 (핵심 수식)
이제 $B$개의 퓨전 병목 토큰 $z_{\text{fsn}} = [z^1_{\text{fsn}}, \ldots, z^B_{\text{fsn}}]$을 도입합니다. 여기서 $B$는 원래 이미지/오디오 토큰 개수보다 훨씬 작습니다 ($B \ll N_v, B \ll N_a$).
각 레이어 $l$에서 다음과 같은 일이 벌어집니다.
- 모달리티 내부 + 병목 토큰과의 Attention: 시각(또는 청각) 토큰 $z^l_i$들은 자기들끼리, 그리고 병목 토큰 $z^l_{\text{fsn}}$과만 정보를 교환합니다.(여기서 $\hat{z}^{l+1}_{\text{fsn}i}$는 해당 모달리티에서 업데이트된 '임시' 병목 토큰입니다.) $$[z^{l+1}_i ||\hat{z}^{l+1}_{\text{fsn}i}] = \text{Transformer}([z^l_i ||z^l_{\text{fsn}}]; \theta_i)$$
- 병목 토큰의 융합 (대칭 업데이트): 시각에서 업데이트된 임시 병목 토큰과 청각에서 업데이트된 임시 병목 토큰의 평균을 내어 진짜 병목 토큰을 갱신합니다.이 평균된 병목 토큰이 다음 레이어로 넘어가며 두 모달리티 사이의 다리 역할을 합니다. $$z^{l+1}_{\text{fsn}} = \text{Avg}_i(\hat{z}^{l+1}_{\text{fsn}i})$$
3-4 융합은 언제부터? (Mid-fusion 전략)
처음부터(레이어 0) 병목 토큰을 쓰면 어떨까요? 저자들의 실험 결과, 초기 레이어에서는 각 모달리티(이미지, 소리) 고유의 저수준(Low-level) 특징을 뽑아내는 데 집중하는 것이 더 좋았습니다.
따라서 처음 $L_f$개의 레이어까지는 각자 따로 학습하다가, 그 이후 레이어부터 병목 토큰을 투입하여 정보를 섞는 'Mid-fusion' 방식이 가장 뛰어난 성능을 보였습니다. 논문에서는 12개의 레이어 중 8번째 레이어($L_f=8$)에서 융합을 시작하는 것이 최적이라고 밝혔습니다.
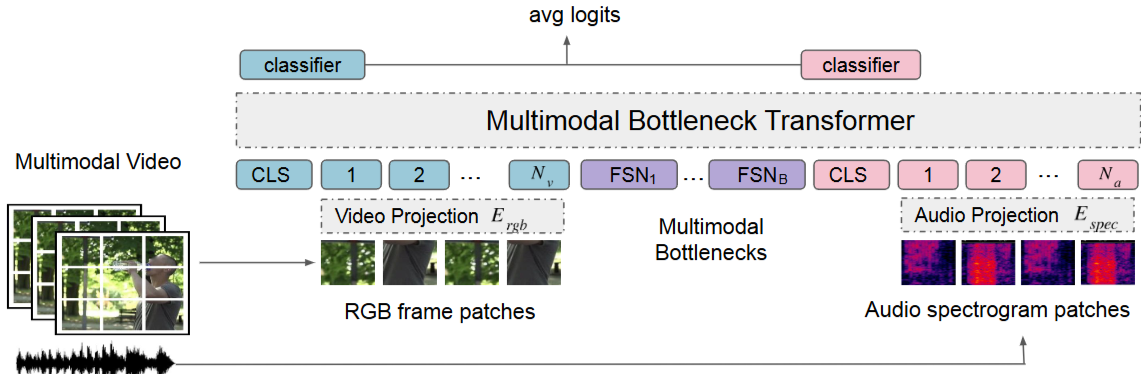
이 이미지는 본 논문에서 제안하는 Multimodal Bottleneck Transformer (MBT)의 아키텍처 개요를 보여줍니다. MBT는 오디오와 비디오라는 두 가지 모달리티의 정보를 융합하여 비디오 분류 작업을 수행하는 것을 목표로 합니다.
입력 (Multimodal Video):
RGB 프레임 패치: 비디오 클립에서 추출된 여러 RGB 프레임이 작은 패치로 나뉩니다. 각 패치는 비디오의 시각적 정보를 나타냅니다.
오디오 스펙트로그램 패치: 비디오와 함께 제공되는 오디오 파형은 로그 멜 스펙트로그램으로 변환된 후 패치로 나뉩니다. 각 스펙트로그램 패치는 오디오의 시간-주파수 정보를 나타냅니다.
프로젝션 (Video Projection E<sub>rgb</sub>, Audio Projection E<sub>spec</sub>):
각 모달리티에서 추출된 패치들은 별도의 선형 프로젝션 레이어를 통과하여 트랜스포머 모델의 입력으로 적합한 임베딩 벡터로 변환됩니다.
토큰 시퀀스:
CLS 토큰: 각 모달리티별로 분류를 위한 특별한 CLS (classification) 토큰이 추가됩니다.
모달리티 토큰: 프로젝션된 RGB 패치 임베딩(총 N_v개)과 오디오 스펙트로그램 패치 임베딩(총 N_a개)이 해당 모달리티의 토큰으로 사용됩니다.
FSN 토큰 (Fusion Bottleneck): 논문의 핵심 아이디어인 '융합 병목(Fusion Bottleneck)'을 나타내는 FSN_1부터 FSN_B까지의 토큰(B개)이 있습니다. 이 토큰들은 두 모달리티 간의 정보 교환을 중재하는 역할을 합니다.
Multimodal Bottleneck Transformer:
이것이 본 논문의 주요 제안인 트랜스포머 기반 모델입니다. 이 인코더는 CLS 토큰, 모달리티 토큰, 그리고 FSN 토큰을 모두 입력으로 받아 처리합니다.
핵심은 FSN 토큰을 통해 모달리티 간의 정보 흐름을 제한한다는 것입니다. 즉, 오디오와 비디오 토큰이 직접적으로 모든 정보를 교환하는 것이 아니라, FSN 토큰을 거쳐 필요한 정보만 압축하고 전달하도록 유도합니다.
출력 (avg logits):
MBT 인코더의 최종 출력에서 각 모달리티의 CLS 토큰 표현이 각각의 classifier를 통과합니다.
두 분류기의 출력 로짓(logits)이 평균되어 최종 예측을 위한 avg logits를 생성합니다.
이 그림은 MBT가 어떻게 시각적(RGB 프레임 패치) 및 청각적(오디오 스펙트로그램 패치) 정보를 통합하고, 특히 '융합 병목(FSN 토큰)'을 통해 계산 효율성을 높이면서도 효과적인 모달리티 융합을 달성하는지를 시각적으로 설명합니다.
4. 실험 결과가 시사하는 바
이 단순하고 우아한 병목 구조의 결과는 매우 강력했습니다.
- 압도적인 데이터 효율성:
- AudioSet 벤치마크에서 기존의 SOTA(State-of-the-art) 모델들이 200만 개의 데이터를 학습해서 얻은 결과를, MBT는 고작 50만 개의 데이터만으로 뛰어넘었습니다 (49.6 mAP 달성). 병목 구조가 불필요한 노이즈 학습을 막아주어 적은 데이터로도 핵심을 잘 파악하게 해준 것입니다.
- 설명 가능한 AI (시각화 결과):
- Attention 맵을 뜯어보니, MBT 모델이 영상을 볼 때 단순히 화면 전체를 보는 게 아니라, '소리가 나는 정확한 근원지'에 집중하고 있음이 확인되었습니다. 병목 토큰이 "오디오 분류를 위해 화면의 저 부분을 유심히 봐!"라고 정확히 지시를 내린 셈입니다.
- 적은 병목 토큰으로도 충분:
- $B=4$ 라는 아주 적은 수의 병목 토큰만으로도 충분히 정보 교환이 일어났습니다.
5. MBT의 PyTorch 구현 구조 (Pseudo-code)
MBT의 핵심은 기존 Vision Transformer(ViT)나 Audio Spectrogram Transformer(AST)의 구조를 거의 그대로 유지하면서, '병목 토큰(Bottleneck Tokens)'을 텐서 조작(Tensor Manipulation)을 통해 어떻게 섞어주는가에 있습니다.
아래는 융합이 시작되는 특정 레이어(Mid-fusion)에서 병목 토큰이 어떻게 작동하는지를 보여주는 PyTorch 수도코드(Pseudo-code)입니다.
import torch
import torch.nn as nn
class MBTFusionLayer(nn.Module):
def __init__(self, dim, num_heads, bottleneck_size):
super().__init__()
# 시각과 청각 각각을 처리할 표준 Transformer Encoder Layer
self.vision_layer = nn.TransformerEncoderLayer(d_model=dim, nhead=num_heads)
self.audio_layer = nn.TransformerEncoderLayer(d_model=dim, nhead=num_heads)
self.B = bottleneck_size
def forward(self, vision_tokens, audio_tokens, bottleneck_tokens):
# vision_tokens: [Batch, N_v, dim]
# audio_tokens: [Batch, N_a, dim]
# bottleneck_tokens: [Batch, B, dim]
# 1. 각 모달리티 토큰의 끝에 병목 토큰을 이어 붙임 (Concatenation)
# v_input shape: [Batch, N_v + B, dim]
v_input = torch.cat([vision_tokens, bottleneck_tokens], dim=1)
# a_input shape: [Batch, N_a + B, dim]
a_input = torch.cat([audio_tokens, bottleneck_tokens], dim=1)
# 2. 각각의 Transformer 레이어 통과 (Self-Attention 수행)
# 이 과정에서 시각 정보와 임시 병목, 청각 정보와 임시 병목이 각각 교류함
v_out = self.vision_layer(v_input)
a_out = self.audio_layer(a_input)
# 3. 출력 텐서에서 모달리티 토큰과 업데이트된 병목 토큰을 다시 분리 (Slicing)
next_vision_tokens = v_out[:, :-self.B, :]
v_bottleneck_out = v_out[:, -self.B:, :] # 시각 정보가 반영된 임시 병목
next_audio_tokens = a_out[:, :-self.B, :]
a_bottleneck_out = a_out[:, -self.B:, :] # 청각 정보가 반영된 임시 병목
# 4. 두 모달리티에서 나온 임시 병목 토큰들의 평균을 계산 (Average)
# 이 토큰이 다음 레이어의 새로운 병목 토큰으로 사용됨
next_bottleneck_tokens = (v_bottleneck_out + a_bottleneck_out) / 2.0
return next_vision_tokens, next_audio_tokens, next_bottleneck_tokens
코드 분석 포인트:
- 복잡한 교차 어텐션(Cross-Attention) 수식을 새로 짜는 것이 아니라, torch.cat을 통해 단순히 시퀀스 길이를 늘려 기존의 Self-Attention 블록에 밀어 넣습니다.
- 출력된 텐서의 마지막 B개의 인덱스만 잘라내어(Slicing) 평균을 내는 것으로 교차 모달 정보 교환을 우아하게 구현했습니다.
6. 베이스라인 모델 비교: MBT vs Perceiver
논문에서 가장 중요한 비교군으로 등장하는 모델은 딥마인드(DeepMind)에서 발표한 Perceiver입니다. 두 모델 모두 멀티모달 데이터의 방대한 연산량을 해결하기 위해 제안되었지만, 접근 방식이 완전히 다릅니다.
| 비교 항목 | Perceiver | MBT (Multimodal Bottleneck Transformer) |
| 핵심 아키텍처 | 비대칭적 교차 어텐션 (Asymmetric Cross-Attention) | 대칭적 병목 어텐션 (Symmetric Bottleneck Attention) |
| 정보 처리 방식 | 모든 입력 데이터를 고정된 크기의 아주 작은 '잠재 배열(Latent Array)'로 한 번에 압축함. | 모달리티 고유의 토큰 흐름을 끝까지 유지하며, '병목 토큰'을 통해서만 정보를 교환함. |
| 계산 복잡도 해결 | 입력($N$)과 잠재 배열($M$) 간의 연산으로 $\mathcal{O}(NM)$ 달성. | 초기 레이어는 각자 처리하고, 후반부에서만 병목을 사용해 연산량 최적화. |
| 장단점 | 입력 크기에 구애받지 않아 매우 긴 시퀀스에 유리하지만, 초기부터 정보가 크게 압축되어 디테일 손실 위험이 있음. | 영상/음성의 공간적, 시간적 특징을 잘 보존하면서도 필요한 맥락만 교환하여 데이터 효율이 매우 뛰어남. |
조금 더 깊은 이해를 위한 부연 설명:
Perceiver는 방대한 비디오와 오디오 배열을 볼 때, 미리 정해둔 소수의 '잠재 벡터'들이 입력 데이터를 향해 쿼리(Query)를 던져 정보를 빨아들이는 방식입니다. 모든 정보가 중앙의 작은 병목으로 한 번에 쏠리는 구조입니다.
반면 MBT는 "각자의 길은 각자 가되, 중간중간 연락책(Bottleneck)만 파견하자"는 철학입니다. ViT가 가지는 이미지 패치들의 공간적 정보, AST가 가지는 주파수의 시간적 흐름을 모델 끝까지 파괴하지 않고 유지합니다. 이 때문에 MBT는 Perceiver보다 훨씬 적은 데이터(약 1/4)만으로도 오디오-비주얼 분류 작업에서 더 뛰어난 성능(SOTA)을 달성할 수 있었습니다.
5. 요약 및 스터디 노트 마무리
한 줄 요약: "멀티모달 데이터를 융합할 때는 냅다 다 섞지 말고, 너무 늦게 섞지도 말고, 적당히 각자 특징을 추출한 중간 단계에서 소수의 병목 토큰을 통해 핵심 정보만 교환하게 만들면 연산량도 줄고 성능도 올라간다."
MBT는 복잡한 수식이나 완전히 새로운 모듈을 발명한 것이 아니라, 데이터가 흘러가는 '경로(Routing)'를 아주 똑똑하게 제한함으로써 연산량과 성능이라는 두 마리 토끼를 잡았습니다. PyTorch의 텐서 조작만으로도 충분히 구현이 가능할 만큼 구조가 명확하다는 점이 이 논문의 또 다른 매력입니다.
개인적인 생각:
이 논문은 단순히 비디오 분류 성능을 높인 것을 넘어, 이질적인 도메인의 데이터를 어떻게 아키텍처 레벨에서 제어하며 섞을 것인가에 대한 훌륭한 인사이트를 제공합니다. 병목 토큰이라는 아이디어는 향후 텍스트나 3D 데이터 등 3개 이상의 모달리티를 융합할 때 확장성 측면에서 매우 유리하게 작용할 것 같습니다.
'1. AI 논문 + 모델 분석 > AI 논문 분석' 카테고리의 다른 글
| [논문 리뷰] DETR: 객체 검출(Object Detection)의 End-to-End 파이프라인 (0) | 2026.02.22 |
|---|---|
| [논문 구현] 멀티모달 병목 트랜스포머(MBT) PyTorch 구현 및 RAVDESS 감정 인식 테스트 (0) | 2026.02.16 |
| [논문 리뷰] CLIP: 텍스트로 이미지를 이해하는 비전 모델 (OpenAI) (0) | 2026.02.12 |
| [논문 리뷰] Bahdanau Attention: 정렬과 번역을 동시에 학습하는 신경망 기계 번역 (0) | 2026.02.09 |
| [논문 리뷰] DenseNet: Densely Connected Convolutional Networks (0) | 2026.01.28 |