딥러닝의 발전 속에서도 한동안 해결하기 어려웠던 과제는 '입력과 출력의 길이가 다른 시퀀스'를 어떻게 처리하느냐였습니다.
본 논문은 두 개의 LSTM을 결합한 Seq2Seq(Sequence-to-Sequence) 구조를 통해 이 문제를 우아하게 해결했습니다.
Sequence to Sequence Learning with Neural Networks
1. 배경: DNN의 한계와 시퀀스 학습
기존의 Deep Neural Networks(DNN)은 고정된 차원의 벡터를 입력받아 고정된 차원의 벡터를 출력하는 구조입니다. 하지만 기계 번역처럼 문장의 길이가 매번 달라지는 시나리오에서는 이러한 고정성(Fixed dimensionality)이 큰 제약이 됩니다.
본 논문은 이러한 한계를 극복하기 위해 가변 길이의 입력을 가변 길이의 출력으로 매핑하는 일반적인 엔드-투-엔드(End-to-End) 방식을 제안합니다.

2. 핵심 방법론: 두 개의 LSTM (Encoder & Decoder)
핵심 아이디어는 하나의 LSTM이 입력 시퀀스를 읽고, 또 다른 LSTM이 출력 시퀀스를 생성하도록 하는 것입니다.
1) Encoder (부호화)
- 입력 시퀀스 $(x_1, \dots, x_T)$를 한 번에 한 타임스텝씩 읽어 들입니다.
- 마지막 타임스텝의 은닉 상태(Hidden State)를 고정된 차원의 벡터 표현 $v$로 취합니다.
- 이 벡터 $v$는 입력 문장 전체의 의미를 압축한 '컨텍스트 벡터' 역할을 합니다.
2) Decoder (복호화)
- 엔코더로부터 전달받은 벡터 $v$를 초기 상태로 하여 타겟 시퀀스 $(y_1, \dots, y_{T'})$를 생성합니다.
- 본질적으로 이 디코더는 $v$라는 조건이 붙은 RNN 언어 모델(RNNLM)입니다.
- 시퀀스의 끝을 알리는 <EOS> 토큰이 나올 때까지 생성을 반복하며 가변 길이 시퀀스를 완성합니다.
3) 수학적 정의
모델은 다음과 같은 조건부 확률을 최대화하도록 학습됩니다.
3. 성능 향상을 위한 3가지 핵심
논문은 기본 Seq2Seq 구조에 세 가지 중요한 기술적 요소를 더해 성능을 비약적으로 끌어올렸습니다.
- 독립된 LSTM 사용: Encoder와 Decoder에 서로 다른 파라미터를 가진 별개의 LSTM을 사용했습니다. 이를 통해 모델의 표현력을 높이고 계산 비용을 효율적으로 관리했습니다.
- Deep LSTM (4개 레이어): 얕은 모델보다 깊은 모델이 훨씬 뛰어난 성능을 보였기에, 4개 층으로 쌓인 심층 LSTM을 채택했습니다.
- 입력 시퀀스 역전(Reversing the Source Sentence) ★: 이 논문의 가장 기발한 수입니다. A, B, C라는 문장을 입력할 때 C, B, A 순서로 뒤집어서 넣는 것입니다.
- 이유: 이렇게 하면 소스 문장의 첫 단어(A)와 타깃 문장의 첫 단어(X) 사이의 거리가 매우 가까워집니다.
- 효과: 단기 의존성(Short-term dependencies)이 강화되어 SGD가 입력과 출력 사이의 연결 고리를 더 쉽게 학습하게 되며, 이는 전체적인 번역 품질 향상으로 이어졌습니다.
4. 실험 및 결과 분석
실험은 WMT'14 영어-프랑스어 번역 태스크에서 진행되었습니다.
모델 사양
- 레이어: 4개 레이어의 LSTM
- 파라미터 수: 3억 8,400만 개 (각 레이어 1,000개 셀, 1,000차원 임베딩)
- 학습 기법: 모멘텀 없는 SGD, 기울기 클리핑(Gradient Clipping), 비슷한 길이끼리 미니배치 구성
성능 (BLEU Score)
| 모델 설정 | BLEU Score | 비고 |
| 기존 SMT (Base) | 33.30 | 전통적인 통계 기반 모델 |
| LSTM 앙상블 (5개) | 34.81 | SMT를 넘어서는 순수 신경망 모델 |
| SMT + LSTM Rescoring | 36.50 | SMT 후보군을 LSTM으로 재순위화 |
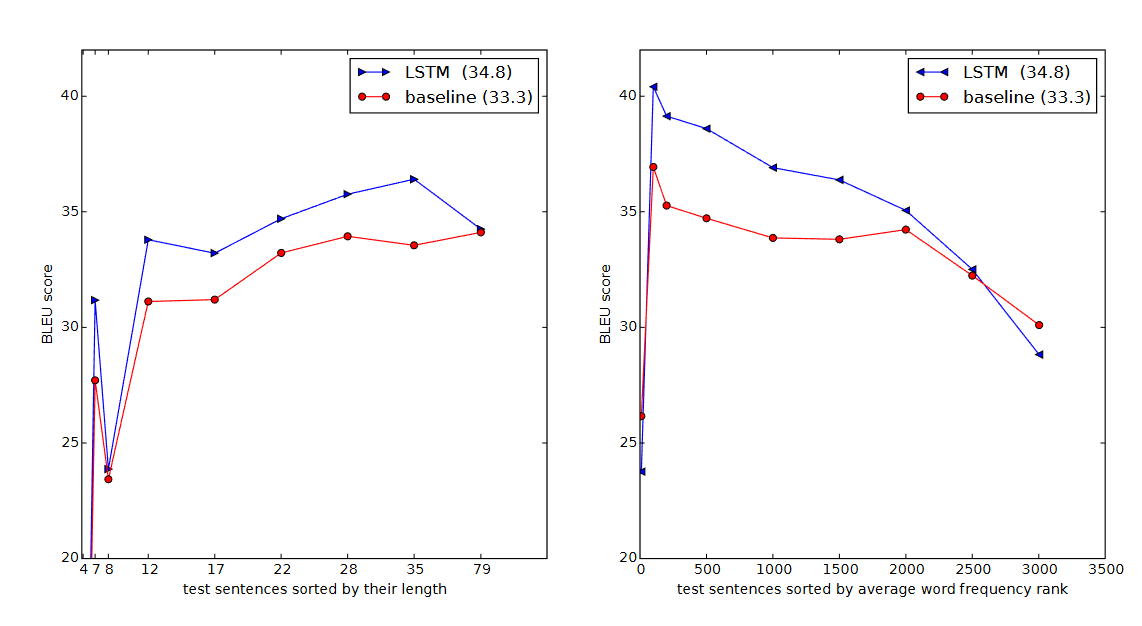
5. 흥미로운 발견: 의미론적 표상
논문은 PCA(주성분 분석) 시각화를 통해 모델이 내부적으로 어떻게 문장을 이해하는지 분석했습니다.
- 문장 구조에 민감: 모델은 단어의 순서와 의미에 민감하게 반응합니다.
- 의미 중심 매핑: 능동태 문장과 수동태 문장이 의미가 같다면, 이들을 벡터 공간상에서 매우 가까운 위치에 매핑한다는 사실이 확인되었습니다.
- 긴 문장에 강함: 역전 트릭 덕분에 기존의 다른 RNN 아키텍처들이 어려워하던 긴 문장 번역에서도 성능 저하 없이 우수한 결과를 보여주었습니다.
6. 결론 및 시사점
본 논문은 대규모 심층 LSTM 모델이 최소한의 구조적 가정만으로도 복잡한 시퀀스 학습 태스크에서 기존 통계 시스템을 압도할 수 있음을 입증했습니다.
특히 "데이터를 뒤집어 넣는 것만으로도 학습 효율이 극대화된다"는 통찰은 딥러닝에서 데이터의 구조적 배치가 최적화에 얼마나 큰 영향을 미치는지 보여주는 아주 중요한 사례로 남았습니다. 이 방식은 이후 Attention 메커니즘과 Transformer의 등장으로 이어지는 시퀀스 모델링의 황금기를 여는 신호탄이 되었습니다.