컴퓨터 비전과 객체 탐지
안녕하세요! 오늘은 AI가 세상을 보는 방법인 컴퓨터 비전(Computer Vision)의 기초와 그 꽃이라고 불리는 객체 탐지(Object Detection) 기술에 대해 깊이 있게 알아보겠습니다. 전통적인 방식부터 최신 YOLO 모델 실습까지 함께 정리해 봅시다.
1. 컴퓨터 비전의 기초
컴퓨터 비전이란?
컴퓨터가 인간처럼 이미지나 영상을 이해하도록 하는 기술입니다. 단순히 사진을 보는 것을 넘어, 그 안에 무엇이 있고 어떤 일이 일어나고 있는지 분석하는 모든 과정을 포함합니다.
대표 프레임워크
- OpenCV: 실시간 이미지 처리 및 전처리의 최강자.
- PyTorch / TensorFlow: 딥러닝 모델 설계와 학습을 위한 핵심 도구.
데이터셋의 종류
모델이 똑똑해지려면 양질의 데이터가 필요합니다.
- COCO: 일상적인 객체 80종, 정밀한 세그멘테이션 제공.
- Open Images: Google 제공, 900만 장 이상의 방대한 데이터.
- KITTI: 자율주행 연구를 위한 실제 도로 데이터.
2. 어노테이션(Annotation): 정답지 만들기
모델에게 "이게 강아지야"라고 알려주는 과정을 어노테이션이라고 합니다.
- Bounding Box: 객체를 사각형으로 감쌈 (객체 탐지용).
- Polygon: 객체의 외곽선을 다각형으로 정밀하게 따냄.
- Segmentation: 픽셀 단위로 객체를 구분.
- Keypoint: 관절이나 얼굴의 특정 지점을 찍음 (포즈 인식용).
3. Object Detection: 무엇이 어디에 있는가?
개념 정리
이미지 내의 객체가 무엇인지(Classification) 맞추고, 어디에 있는지(Localization) 바운딩 박스로 표시하는 기술입니다.

전통적인 기법 (Traditional Methods)
딥러닝 이전에는 사람이 직접 특징을 설계(Handcrafted)했습니다.
- 특징 추출: HOG(경계선 추출), SIFT(회전/크기에 강한 특징점) 등을 사용.
- 분류: 추출된 특징을 SVM 같은 머신러닝 분류기에 입력.
- 탐색: 슬라이딩 윈도우 방식으로 이미지 전체를 훑음.
한계: 배경이 복잡하거나 객체 크기가 변하면 성능이 급격히 떨어집니다.
딥러닝 기반 기법 (Deep Learning)
딥러닝의 등장으로 성능이 비약적으로 발전했습니다.
① 2단계 탐지 (Two-Stage Detection)
- 방식: "객체가 있을 법한 곳을 먼저 찾고(Region Proposal) → 그 안에서 정밀하게 분류".
- 모델: R-CNN, Fast R-CNN, Faster R-CNN.
- 장점: 정확도가 매우 높음.
- 단점: 속도가 느려 실시간 적용이 어려움.
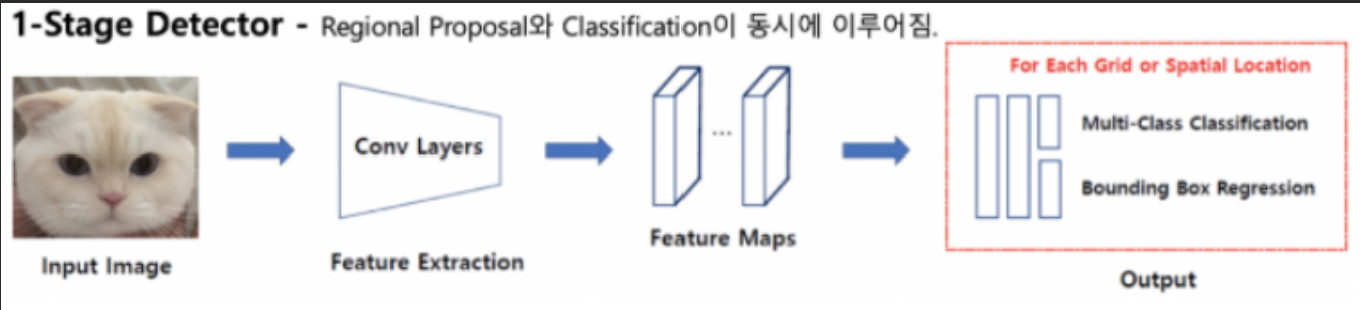
② 1단계 탐지 (One-Stage Detection)
- 방식: "이미지를 한 번만 보고 위치와 종류를 동시에 예측".
- 모델: YOLO, SSD, RetinaNet.
- 장점: 속도가 매우 빨라 실시간 영상 처리에 적합.
- 단점: 작은 객체 탐지 정확도가 상대적으로 낮을 수 있음 (최신 버전에서 많이 개선됨).

4. YOLO (You Only Look Once) 실습
YOLO는 현재 산업 현장에서 가장 많이 쓰이는 모델입니다. v8부터는 Ultralytics 라이브러리를 통해 매우 쉽게 사용할 수 있습니다.
PascalVOC 데이터셋 변환 및 학습
XML 형식의 어노테이션을 YOLO 형식(.txt)으로 변환하여 학습을 진행합니다.
# 1. YOLO 모델 로드 (n, s, m, l, x 중 선택)
from ultralytics import YOLO
model = YOLO('yolov8s.pt')
# 2. 학습 시작
results = model.train(
data='custom_voc.yaml', # 데이터 경로 및 클래스 정보가 담긴 파일
epochs=10,
imgsz=640,
device=0
)
YOLO 어노테이션 구조: [class_id] [x_center] [y_center] [width] [height] (모두 0~1 사이로 정규화)
5. 모델 성능은 어떻게 평가할까? (Metrics)
학습된 모델이 얼마나 잘하는지 판단하는 지표들입니다.
- IoU (Intersection over Union): 실제 박스와 예측 박스가 얼마나 겹치는가? (1에 가까울수록 정확)
- Precision(정밀도): 모델이 객체라고 한 것 중 진짜 객체 비율.
- Recall(재현율): 실제 객체 중 모델이 놓치지 않고 찾은 비율.
- mAP (mean Average Precision): 모든 클래스에 대한 정밀도의 평균. 모델의 종합 성적표!
- mAP@50: IoU 0.5 기준의 성능.
- mAP@50-95: 더 엄격한 기준으로 측정한 성능.
- FPS: 1초에 몇 프레임을 처리하는가? (속도 지표)
마무리하며
컴퓨터 비전은 단순한 이미지 분석을 넘어 자율주행, 의료, 보안 등 우리 삶 전반에 깊숙이 들어와 있습니다. 특히 YOLO와 같은 모델은 속도와 정확도를 모두 잡으며 실시간 AI 서비스의 핵심이 되고 있습니다.
오늘의 핵심 요약:
- 2-Stage는 정확하지만 느리고, 1-Stage(YOLO)는 빠르다!
- 모델 성능 평가는 mAP와 IoU를 확인하자.
- Ultralytics를 사용하면 누구나 쉽게 최신 객체 탐지 모델을 구현할 수 있다.
'개념 정리 step2 > 멀티모달(Multi-modal)' 카테고리의 다른 글
| [Deep Learning] TensorFlow 기초와 날씨 분류 모델 실습 (0) | 2026.01.12 |
|---|---|
| [CV Archive] YOLOv8 Segmentation: 스타벅스 로고 추출하기 (0) | 2026.01.11 |
| [YOLO] 축구 영상 객체 탐지 프로젝트: Nano vs Small 모델 성능 비교 분석 (0) | 2026.01.10 |
| YOLOv8을 이용한 이안류 탐지 및 Segmentation 기초 (0) | 2026.01.08 |
| [OpenCV] Open Source Computer Vision Library 개념 정리 (0) | 2026.01.06 |