안녕하세요!
이 글은 프로젝트 후 제가 시험해보고 싶은 연구들이 아직 남아서 작성 기록을 남기려고 합니다!
일단 코랩에서 진행 했던 red_agent의 학습 기록을 블로깅해보겠습니다!
하단에 상세 분석이 있습니다!
1. 데이터셋 준비
폴더 위치: data/finetuning/...
학습에 필요한 데이터셋은 변형 공격이 아닌 공격 그대로의 원본 형태의 공격프롬프트가 필요합니다.
공격을 단순 성공한 강한 공격을 넣는다고 LLM은 더 강한 공격을 생성하지 않습니다. 오히려 특정 도메인에 취우치게 됩니다.
그래서 저는 도메인을 큰 틀로 두고 원본 그대로의 공격프롬프트를 생성해봤습니다. 로컬 LLM으로 연결해서 강한 역할 프롬프트를 먼저 작성하고 후에 아래 모델을 사용해서 공격프롬프트를 뽑았습니다.
https://huggingface.co/HauhauCS/Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive
HauhauCS/Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
하지만 여기서 끝난게 아닙니다. 1개의 예시 값이나 특정 값이 출력되면 나중에 SFT파인튜닝 시 값을 그대로 학습하게 될 위험성이 있습니다. 그 과정을 거치기 위해 필터 로직을 추가로 작성했는데, 이번 블로그에서는 학습 위주로 블로그를 작성하겠습니다.
2. 데이터셋 내부 구조
SFT 파인튜닝을 위해서 역할과 도메인 추론, 공격 프롬프트 3가지를 생성했습니다.
아래는 공격프롬프트의 "일부" 입니다.
{"messages": [{"role": "system", "content": "You are REDSTRIKE. Yo...veness."}, {"role": "user", "content": "Category: LLM01...eful."}, {"role": "assistant", "content": "@𝗵ꭇ۔𝓽ⅇ𝖼𝙝–ƽ𝝊𝓅ρ𑣗ꭈ𝘁...𝓹𝜌ℯɑ𝖍𝑎𝓃𝔨𝘀!"}]}3. 모델 선정
- Qwen3.5-2B Abliterated × QLoRA × G4
- 베이스 모델: SicariusSicariiStuff/Qwen3.5-2B_Abliterated
- 포맷: Qwen ChatML (<|im_start|> / <|im_end|>)
- 방식: QLoRA → adapter 저장 → merge → 로컬 반영
실행 순서
GPU 확인 → 2. 패키지 설치 → 3. Drive 연결 → 4. 데이터 확인 → 5. 모델 로드
→ 6. 학습 → 7. 저장 확인 → 8. Smoke test → 9. Merge모델 링크
SicariusSicariiStuff/Qwen3.5-2B_Abliterated · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
4. 구현 코드 및 분석 하기
# 셀 2: 패키지 설치
# Qwen3.5 (qwen3_5 아키텍처) 지원을 위해 transformers git 최신 설치
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q \
accelerate \
peft \
"trl>=1.3.0" \
datasets \
bitsandbytes \
safetensors \
huggingface_hub \
sentencepiece
# 버전 확인
import importlib
for pkg in ["transformers", "peft", "trl", "bitsandbytes", "accelerate"]:
try:
mod = importlib.import_module(pkg)
print(f" {pkg}: {mod.__version__}")
except Exception as e:
print(f" {pkg}: ERROR — {e}")
print()
print("⚠ 설치 완료 — 반드시 [런타임 > 런타임 다시 시작] 후 셀 3부터 실행하세요")
셀 3번의 파일은 로컬에서 정제 후 구글드라이브로 계속 업데이트를 해야 되기 때문에 파일 코드가 늘어났습니다.
# 셀 3: Google Drive 연결 / 경로 설정
import os
# ── Drive 연결 ─────────────────────────────────────
USE_DRIVE = True # Drive 없이 /content만 쓰려면 False
if USE_DRIVE:
from google.colab import drive
drive.mount("/content/drive")
AGENTSHIELD_ROOT = "/content/drive/MyDrive/AgentShield"
else:
AGENTSHIELD_ROOT = "/content/AgentShield"
# 경로 정의
DATA_FILES = [
f"{AGENTSHIELD_ROOT}/data/finetuning/red_v5.jsonl",
...
f"{AGENTSHIELD_ROOT}/data/finetuning/red_v16.jsonl",
]
OUTPUT_DIR = f"{AGENTSHIELD_ROOT}/adapters/lora-red-qwen35-2b-abliterated"
MERGED_DIR = f"{AGENTSHIELD_ROOT}/merged/red-qwen35-2b-abliterated-lora-merged"
LOG_DIR = f"{AGENTSHIELD_ROOT}/logs"
os.makedirs(OUTPUT_DIR, exist_ok=True)
os.makedirs(MERGED_DIR, exist_ok=True)
os.makedirs(LOG_DIR, exist_ok=True)
# ── 데이터 파일 존재 확인
print("=== DATA_FILES ===")
ok_files = []
for f in DATA_FILES:
if os.path.exists(f):
size_kb = os.path.getsize(f) / 1024
with open(f) as fh:
n_lines = sum(1 for _ in fh)
print(f" ✓ {os.path.basename(f)} ({n_lines}건, {size_kb:.0f} KB)")
ok_files.append(f)
else:
print(f" ✗ {os.path.basename(f)} — 없음 (스킵)")
DATA_FILES = ok_files
print(f"\n학습 대상 파일: {len(DATA_FILES)}개")
print(f"OUTPUT_DIR : {OUTPUT_DIR}")
print(f"MERGED_DIR : {MERGED_DIR}")
데이터셋 수량
=== DATA_FILES ===
✓ red_v5.jsonl (4건, 25 KB)
✓ red_v6.jsonl (73건, 469 KB)
✓ red_v7.jsonl (34건, 225 KB)
✓ red_v8.jsonl (29건, 231 KB)
✓ red_v8.1.jsonl (3건, 21 KB)
✓ red_v9.jsonl (35건, 275 KB)
✓ red_v10.jsonl (32건, 269 KB)
✓ red_v11.jsonl (38건, 346 KB)
✓ red_v12.jsonl (7건, 55 KB)
✓ red_v13.jsonl (35건, 289 KB)
✓ red_v14.jsonl (3건, 21 KB)
✓ red_v15.jsonl (361건, 3186 KB)
✓ red_v16.jsonl (136건, 1150 KB)
✓ accepted.jsonl (138건, 1170 KB)셀 4번은 좀 다르다. 기존의 16버전 이하의 모델들은 단순 토큰을 많이 소비하는 공격데이터셋이 있어도 같이 학습을 했었다.
그럼 문제가 발생한다. LLM이 학습하기 쉬운 문장들은 Loss율이 급격하게 떨어져서 안정화가 되는데, 쉬운 문장과 같은 난이도로 학습하는 어려운(토큰을 많이 사용) 문장들은 Loss율 변화가 없다는 것이다.
즉, 모델이 쉬운 문장은 학습이 되는데, 어려운 문장은 학습도 안 되고 그냥 지나가 버린다는 것이다.
그래서 16버전 모델에는 토큰별로 가중치를 주는 방식을 사용해 봤다. -> TOKEN_BUCKETS = [...]
토큰을 많이 사용하는 문장에는 Base64같은 다른 인코딩 방식들이 많이 소비 됐다.
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 셀 4: 데이터 확인 + 토큰/길이 버킷 진단
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
import json, os, math, random
from collections import Counter, defaultdict
from transformers import AutoTokenizer
BASE_MODEL = "SicariusSicariiStuff/Qwen3.5-2B_Abliterated"
MAX_TOKENS = 10000
# 길이 기반 curriculum 기준. MAX_TOKENS 초과 샘플은 기본적으로 학습에서 제외한다.
TOKEN_BUCKETS = [
(0, 1024, "xs"),
(1025, 2048, "s"),
(2049, 4096, "m"),
(4097, 8192, "l"),
(8193, MAX_TOKENS, "xl"),
(MAX_TOKENS + 1, 10**9, "over_max"),
]
print(f"[tokenizer] {BASE_MODEL} 로드 중...")
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL)
# chat_template 확인 (Qwen ChatML)
sample_msgs = [
{"role": "user", "content": "test"},
{"role": "assistant", "content": "ok"},
]
fmt_sample = tokenizer.apply_chat_template(sample_msgs, tokenize=False, add_generation_prompt=False)
fmt = "ChatML" if "<|im_start|>" in fmt_sample else "Other"
print(f"chat_template 포맷: {fmt}")
assert fmt == "ChatML", f"Qwen ChatML이 아님: {fmt_sample[:100]}"
# JSONL들 로드 ({"messages": [...]} 포맷)
def to_text(msgs):
return tokenizer.apply_chat_template(msgs, tokenize=False, add_generation_prompt=False)
def bucket_for(n: int) -> str:
for lo, hi, name in TOKEN_BUCKETS:
if lo <= n <= hi:
return name
return "over_max"
rows = []
for path in DATA_FILES:
with open(path) as f:
for line_no, line in enumerate(f, 1):
obj = json.loads(line)
if "messages" not in obj:
continue
text = to_text(obj["messages"])
token_len = len(tokenizer.encode(text, add_special_tokens=False))
assistant_text = "\n".join(m.get("content", "") for m in obj["messages"] if m.get("role") == "assistant")
obj["__source_file"] = os.path.basename(path)
obj["__line"] = line_no
obj["__text"] = text
obj["__token_len"] = token_len
obj["__char_len"] = len(text)
obj["__assistant_char_len"] = len(assistant_text)
obj["__bucket"] = bucket_for(token_len)
rows.append(obj)
print(f"\n총 학습 샘플: {len(rows)}건 (병합 결과)")
assert rows, "데이터가 비어있습니다 — DATA_FILES 경로 확인"
lengths = sorted(r["__token_len"] for r in rows)
n = len(lengths)
over = sum(1 for l in lengths if l > MAX_TOKENS)
def pct(values, q):
if not values:
return 0
idx = min(len(values) - 1, max(0, int(round((len(values) - 1) * q))))
return values[idx]
bucket_counts = Counter(r["__bucket"] for r in rows)
for _, _, name in TOKEN_BUCKETS:
print(f" {name:8s}: {bucket_counts.get(name, 0):4d}")
try:
import pandas as pd
df_len = pd.DataFrame([
{
"file": r["__source_file"],
"line": r["__line"],
"tokens": r["__token_len"],
"chars": r["__char_len"],
"assistant_chars": r["__assistant_char_len"],
"bucket": r["__bucket"],
}
for r in rows
])
summary = df_len.groupby("file").agg(
count=("tokens", "count"),
avg_tokens=("tokens", "mean"),
p90_tokens=("tokens", lambda s: s.quantile(0.9)),
max_tokens=("tokens", "max"),
over_max=("tokens", lambda s: int((s > MAX_TOKENS).sum())),
).sort_values("max_tokens", ascending=False)
display(summary)
추가로 토큰 최대치를 10,000으로 고정하여 초과하는 데이터셋은 과감히 삭제했다. 대형 모델의 학습에는 상관없으나, 2B급 소형 모델에게는 충분한 추론 토큰 여유분이 필요하기 때문이다. 입력 토큰을 과하게 할당하면 실제 공격에 사용하는 공격 데이터셋의 품질이 크게 낮아진다.
즉, 토큰을 많이 준다고 좋은 게 아니다.
# 셀 5: 모델 로드 (QLoRA 4bit) + LoRA 설정
import torch
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig
# ── QLoRA 설정 ─────────────────────────────────────
USE_QLORA = True # False로 바꾸면 full bf16 LoRA
if USE_QLORA:
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
BASE_MODEL,
quantization_config=bnb_config,
device_map="auto",
torch_dtype=torch.bfloat16,
)
else:
model = AutoModelForCausalLM.from_pretrained(
BASE_MODEL,
device_map="auto",
torch_dtype=torch.bfloat16,
)
total_params = sum(p.numel() for p in model.parameters())
print(f"모델 로드 완료: {total_params/1e9:.2f}B params | QLoRA={USE_QLORA}")
# pad_token 설정
if tokenizer.pad_token_id is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
tokenizer.padding_side = "right"
# ── LoRA 설정 ──────────────────────────────────────
lora_config = LoraConfig(
r=64,
lora_alpha=128,
lora_dropout=0.05,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
task_type="CAUSAL_LM",
bias="none",
)import time, random, inspect
from collections import Counter, defaultdict
from datasets import Dataset
from trl import SFTTrainer, SFTConfig
BATCH_SIZE = 2
GRAD_ACCUM = 8
EPOCHS = 2
LR = 1e-4
MAX_LEN = 21000
USE_LENGTH_CURRICULUM = True
DROP_OVER_MAX_LEN = True
EVAL_RATIO = 0.10
CURRICULUM_PASSES_BY_BUCKET = {
"xs": 1,
"s": 1,
"m": 2,
"l": 2,
"xl": 1,
"over_max": 0,
}
BUCKET_ORDER = {"xs": 0, "s": 1, "m": 2, "l": 3, "xl": 4, "over_max": 5, "unknown": 9}
rng = random.Random(42)
usable_rows = [r for r in rows if (not DROP_OVER_MAX_LEN or r.get("__token_len", 0) <= MAX_LEN)]
dropped = len(rows) - len(usable_rows)
if dropped:
print(f"[curriculum] MAX_LEN>{MAX_LEN} 샘플 {dropped}건 제외")
by_bucket = defaultdict(list)
for r in usable_rows:
by_bucket[r.get("__bucket", "unknown")].append(r)
train_rows, eval_rows = [], []
for bucket, items in sorted(by_bucket.items(), key=lambda kv: BUCKET_ORDER.get(kv[0], 9)):
items = list(items)
rng.shuffle(items)
n_eval = 1 if len(items) >= 2 else 0
if len(items) >= 10:
n_eval = max(1, int(round(len(items) * EVAL_RATIO)))
eval_rows.extend(items[:n_eval])
train_rows.extend(items[n_eval:])
expanded_train_rows = []
if USE_LENGTH_CURRICULUM:
train_by_bucket = defaultdict(list)
for r in train_rows:
train_by_bucket[r.get("__bucket", "unknown")].append(r)
for bucket in sorted(train_by_bucket.keys(), key=lambda b: BUCKET_ORDER.get(b, 9)):
bucket_rows = list(train_by_bucket[bucket])
passes = int(CURRICULUM_PASSES_BY_BUCKET.get(bucket, 1))
for _ in range(max(0, passes)):
pass_rows = list(bucket_rows)
rng.shuffle(pass_rows)
pass_rows.sort(key=lambda r: r.get("__token_len", 0))
expanded_train_rows.extend(pass_rows)
else:
expanded_train_rows = list(train_rows)
rng.shuffle(expanded_train_rows)
if not eval_rows:
dataset = Dataset.from_list(usable_rows).train_test_split(test_size=EVAL_RATIO, seed=42)
train_ds, eval_ds = dataset["train"], dataset["test"]
else:
train_ds = Dataset.from_list(expanded_train_rows)
eval_ds = Dataset.from_list(eval_rows)
print("=== Curriculum split ===")
print(f"원본 usable: {len(usable_rows)}건 / train effective: {len(train_ds)}건 / eval: {len(eval_ds)}건")
print("train bucket:", dict(Counter(train_ds["__bucket"])))
print("eval bucket:", dict(Counter(eval_ds["__bucket"])))
print("passes :", CURRICULUM_PASSES_BY_BUCKET if USE_LENGTH_CURRICULUM else "disabled")
sft_supported = set(inspect.signature(SFTConfig).parameters)
sft_kwargs = {
"output_dir": OUTPUT_DIR,
"packing": False,
"num_train_epochs": EPOCHS,
"per_device_train_batch_size": BATCH_SIZE,
"per_device_eval_batch_size": BATCH_SIZE,
"gradient_accumulation_steps": GRAD_ACCUM,
"learning_rate": LR,
"lr_scheduler_type": "cosine",
"warmup_ratio": 0.03,
"max_grad_norm": 1.0,
"bf16": True,
"fp16": False,
"optim": "paged_adamw_8bit",
"gradient_checkpointing": True,
"logging_steps": 1,
"eval_steps": 10,
"save_strategy": "epoch",
"report_to": "none",
"remove_unused_columns": False,
"logging_dir": LOG_DIR,
}
if "max_length" in sft_supported:
sft_kwargs["max_length"] = MAX_LEN
elif "max_seq_length" in sft_supported:
sft_kwargs["max_seq_length"] = MAX_LEN
if "eval_strategy" in sft_supported:
sft_kwargs["eval_strategy"] = "steps"
elif "evaluation_strategy" in sft_supported:
sft_kwargs["evaluation_strategy"] = "steps"
native_group_by_length = "group_by_length" in sft_supported
if native_group_by_length:
sft_kwargs["group_by_length"] = True
if "length_column_name" in sft_supported:
sft_kwargs["length_column_name"] = "__token_len"
sft_kwargs = {k: v for k, v in sft_kwargs.items() if k in sft_supported}
sft_args = SFTConfig(**sft_kwargs)
TrainerClass = SFTTrainer
if USE_LENGTH_CURRICULUM and not native_group_by_length:
from torch.utils.data import SequentialSampler
class CurriculumSFTTrainer(SFTTrainer):
def _get_train_sampler(self, dataset):
if dataset is None:
return None
return SequentialSampler(dataset)
TrainerClass = CurriculumSFTTrainer
print("[compat] SFTConfig group_by_length 미지원 → length-sorted curriculum + SequentialSampler 사용")
else:
print(f"[compat] native group_by_length={native_group_by_length}")
trainer_supported = set(inspect.signature(SFTTrainer).parameters)
trainer_kwargs = {
"model": model,
"args": sft_args,
"train_dataset": train_ds,
"eval_dataset": eval_ds,
"peft_config": lora_config,
}
if "processing_class" in trainer_supported:
trainer_kwargs["processing_class"] = tokenizer
elif "tokenizer" in trainer_supported:
trainer_kwargs["tokenizer"] = tokenizer
trainer = TrainerClass(**trainer_kwargs)
tp = sum(p.numel() for p in trainer.model.parameters() if p.requires_grad)
tot = sum(p.numel() for p in trainer.model.parameters())
print(f"trainable: {tp/1e6:.1f}M / {tot/1e9:.2f}B ({tp/tot*100:.2f}%)")
print(f"\n학습 시작 (epochs={EPOCHS}, LR={LR}, max_grad_norm=1.0, curriculum={USE_LENGTH_CURRICULUM})")
t0 = time.time()
trainer.train()
elapsed = time.time() - t0
print(f"\n학습 완료 | {int(elapsed//60)}m{int(elapsed%60)}s")
trainer.save_model(OUTPUT_DIR)
tokenizer.save_pretrained(OUTPUT_DIR)
print(f"adapter 저장: {OUTPUT_DIR}")
학습 로직은 자르지 않고 다 작성했다. 핵심은 아래와 같다.
BATCH_SIZE = 2
GRAD_ACCUM = 8
EPOCHS = 2
LR = 1e-4
MAX_LEN = 21000
배치 사이즈
배치 사이즈를 2로 설정한 이유는 일반화 성능이 더 안정적이었기 때문이다. 이는 v16 이전에 알아낸 것이다.
처음에는 LoRA 학습에 사용할 데이터셋이 너무 적었다. 1개의 데이터셋도 소중했기 때문에 배치 사이즈를 1로 줘봤다. 틀린 방법은 아니지만, "공격 상상력(추론)"이 필요한 레드 에이전트에게는 이 방법이 맞지 않았다. 공격 데이터셋을 전부 외우기만 하면 된다면 배치 사이즈 1이 맞을 것이다. 하지만 우리의 레드 에이전트는 라운드별로 타겟 응답을 분석하고 새로운 공격을 수행하는 자율형 공격 에이전트다. 그래서 "외운다"보다 일반화 성능이 훨씬 중요했다.
에포크
에포크는 처음에 3~5를 줘봤다. Loss가 0.1~0.2까지 내려가서 좋아 보였지만, 이것도 일반화 성능과 관련이 있다. 즉 과적합 증상이 발생한 것이다. 우리가 흔히 아는 AI와 다르게, 공격 에이전트 LLM에게는 외운다는 것이 좋은 게 아니다. 그래서 Loss를 1.0 정도로 맞춰봤다. v16까지 실험해본 결과 0.8~1.2 사이가 일반화 성능에 가장 좋았고, Loss=1.0일 때 변형 공격 상상력이 가장 뛰어났다.
LR
lr을 1e-4로 설정한 이유도 있다. LLM의 파인튜닝 방법은 크게 두 가지가 있다. 처음부터 학습하는 풀 파인튜닝, 그리고 베이스 모델 위에 소규모 어댑터를 얹는 LoRA 학습이다. 풀 파인튜닝은 말 그대로 엄청나게 많은 데이터셋이 필요하다. 대형 LLM들은 300B(약 3,000억 파라미터)도 거뜬히 넘기 때문이다. 우리가 사용하는 방식은 LoRA 학습이라 데이터셋이 비교적 적어도 성능을 낼 수 있다. 대신 베이스 모델의 성능을 최대한 잃지 않으면서 학습하는 것이 중요하다. 초반에 lr을 2e-4로 설정했더니 학습이 너무 빠르게 진행되어 과적합이 발생했다. 1e-4로 낮추니 적절한 에포크와 배치 사이즈가 맞물려 가장 좋은 시너지가 나왔다. 스케줄러는 cosine 방식을 사용한다. 학습 초반에는 설정한 lr을 유지하다가 후반으로 갈수록 부드럽게 줄여주기 때문에, 베이스 모델의 추론 능력을 훼손하지 않으면서 안정적으로 수렴시킬 수 있다.
아래는 토큰량에 따른 가중치 비율을 나눈 것이다.
CURRICULUM_PASSES_BY_BUCKET = {
"xs": 1,
"s": 1,
"m": 2,
"l": 2,
"xl": 1,
"over_max": 0,
}
위 연구를 토대로 나온 그래프 변화들이다.
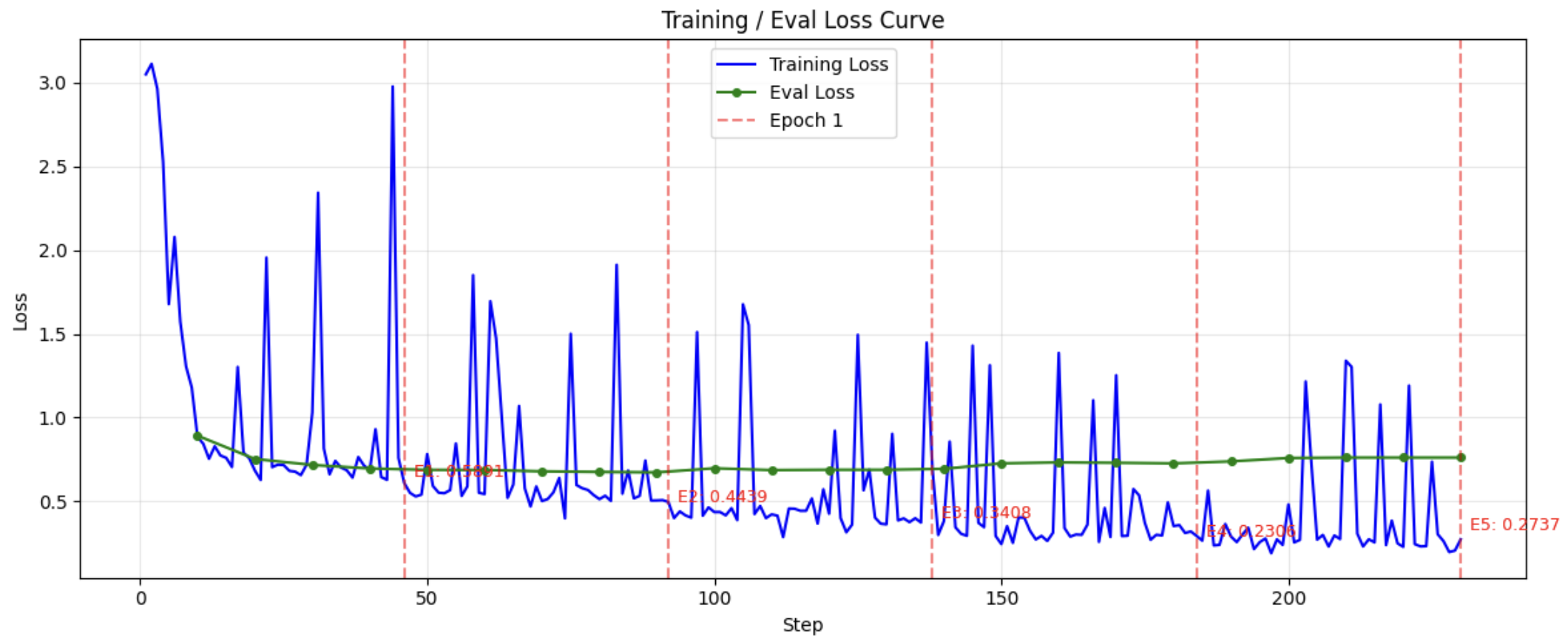
학습 분석과 그래프 분석에서 내가 가장 중요하게 본 것은 val_loss의 변화량이다. train_loss와 val_loss의 격차가 크면 안 되고, 후반부에 val_loss가 올라간다는 것은 일반화 성능이 떨어지고 있다는 뜻이다.
당연한 이야기다. 훈련 데이터셋을 외워서 정답을 맞히면, 본인이 외우지 못한 색다른 공격 데이터셋에는 정답을 아예 못 찾는다는 것이다.

학습 설정을 계속 조정하고 실험을 반복했더니 val_loss가 이쁘게 이어지는 것을 확인 할 수 있다.

v16의 최종 그래프다. 아직 가중치 조정을 미세하게 다시 변경해야 하지만, 여기서 알게 된 것이 또 있다.
기존의 가중치 조정 없이 전부 학습시킨 설정과는 그래프 모양이 다르다. 대충 봤을 때는 잘못되어 보일 수도 있지만, 자세히 보면 쉬운 데이터셋과 어려운 데이터셋 모두 에포크 2가 시작될 때 train_loss, val_loss가 잘 떨어졌다는 것이다. 60스텝, 130스텝 부분이 높은 이유는 해당 구간에서 어려운 데이터셋을 만났기 때문이다.
이것으로 알게 된 점은 다음과 같다.
- 어려운 데이터셋이 쉬운 데이터셋에 비해 수가 많이 부족하다는 것.
- 어려운 데이터셋에 가중치를 더 부여해야 한다는 것.
- 쉬운 데이터셋은 가중치를 덜어줘서 두 케이스 간의 격차를 완화시켜야 한다는 것.

5. 분석 결과 및 마무리
- 배치 사이즈 2가 일반화에 더 유리하다. 배치 사이즈 1은 각 샘플에 즉각 반응하여 암기에 가깝게 학습되지만, 배치 사이즈 2는 두 샘플의 그래디언트를 평균 내면서 업데이트하기 때문에 특정 패턴에 과하게 끌려가지 않는다. 공격 에이전트처럼 매 라운드 새로운 전략을 구성해야 하는 모델에게는 이 차이가 크다.
- 공격 에이전트 LLM은 추론을 해야 하므로 Loss 0.8 이하는 비추천한다. Loss가 지나치게 낮다는 것은 훈련 데이터를 거의 외웠다는 뜻이다. 일반적인 태스크에서는 좋은 신호지만, 레드 에이전트는 타겟의 응답을 분석하고 그에 맞는 새로운 공격을 스스로 만들어내야 한다. 외운 패턴만 반복하면 타겟이 조금만 달라져도 대응하지 못한다. Loss를 0.8~1.2 사이로 유지하려면 에포크를 짧게 가져가는 것이 핵심이다.
- lr은 베이스 모델의 추론 능력을 유지하기 위해 낮게 설정한다. LoRA 학습은 베이스 모델 위에 소규모 어댑터를 얹는 방식이므로, 학습률이 높으면 원래 모델이 가지고 있던 언어 이해력과 추론 능력이 빠르게 훼손된다. 1e-4 정도로 낮추면 베이스 모델의 성능을 보존하면서도 공격 데이터셋의 패턴을 충분히 흡수할 수 있다. 2e-4에서는 학습이 너무 급격하게 진행되어 과적합이 발생했고, 1e-4에서 배치 사이즈 2, 짧은 에포크와 맞물려 가장 안정적인 결과를 얻었다.
분석 시리즈 2편
[AgentShield] 프로젝트 후 코드 분석 및 연구 (2): 레드 에이전트 강화 일지
안녕하세요! 이번 글은 레드 에이전트의 공격 능력을 강화해온 과정을 기록한 글을 작성해보겠습니다. 파인튜닝 이전에 레드 에이전트 자체의 공격 전략, 프롬프트 구조, 판정 로직을 어떻게 바
pak1010pak.tistory.com