안녕하세요! 이번 gemma4가 나오고 오픈소스 llm에 더욱 관심이 많아져서 개인 llm을 로컬에서 사용해보고 싶단 생각이 강하게 들었습니다. 파인튜닝도 직접 하고 파라미터, ModelFile도 직접 작성하면서 계속 사용할 저만의 LLM을 만들고 싶습니다.
그래서 이번에 맥북 프로 16 M5 18코어, 40 코어 GPU, 48gb를 과감히 질렀어요!
사용하고 싶은 베이스모델은 gemma4 26b MOE 버전입니다.
gemma4 설치는 아래 블로그에서 다뤘습니다.
[모델 분석] 오픈 소스 모델 Gemma 4 설치 및 사용하기
안녕하세요!이번에 새로 구글(Google DeepMind)에서 새롭게 공개한 최신 오픈 모델인 Gemma 4가 나왔습니다.밴치마크 성능이 좋다고 해서 로컬로도 실제 돌려보고 싶다는 생각이 들더라고요! 모델에
pak1010pak.tistory.com
먼저 허깅 페이스에서 본인 컴퓨터(노트북)에 맞는 모델 크기를 고민해 보시면 됩니다. 아래는 요즘 24b ~ 32b 사이의 핫한 모델들을 검색해 봤습니다. (Jackrong/Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled 이 모델도 클로드 4.6의 핵심 특징을 계승했다고 하는데 나중에 한 번 사용하고 싶네요!)

저는 이번 프로젝트가 보안 관련이여서 보안과 관련해서 파인튜닝 및 모델 설정을 하고 싶었습니다. 그래서 허깅페이스에 있는 Jiunsong/supergemma4-26b-uncensored-gguf-v2 모델을 선택했어요!
Jiunsong/supergemma4-26b-uncensored-gguf-v2 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
모델 특징은 Fast 라인의 지능과 Uncensored의 자유도가 있습니다. AI의 도덕적 허들 때문에 답변을 회피하거나 딱딱한 페르소나에 갇히지 않도록 설계되었습니다. 제 의도에 맞게 가감 없이 작업을 수행합니다.
두 번째로 기존 Gemma 4 베이스보다 지능(Logic, Code)과 속도(Speed)가 검증된 'Fast' 라인의 가중치를 계승했습니다.
세 번째로 가장 큰 특징은 '중립적인 템플릿'입니다. 특정 질문이 들어왔을 때 모델이 코딩 모드나 특정 작업 모드로 급격히 전환되는 고질적인 버그를 방지하여, 대화의 흐름이 훨씬 자연스럽고 예측 가능하게 설계되었습니다.
1. Modelfile 적용 및 실행 방법
먼저 Modelfile (시스템 프롬프트)에 대해서 설명드리겠습니다. AI의 '본성'과 '직업'으로 딱 생각하시면 편합니다.
- 역할: 모델의 영구적인 자아, 말투, 핵심 규칙, 절대 어기면 안 되는 보안 지침을 설정합니다.
- 작동 방식: 모델이 켜질 때 가장 먼저 뇌에 각인되는 정보입니다.
주의점: 여기에 "어제 짰던 코드", "특정 해킹 페이로드 예시 100개" 같은 잡다한 기억을 계속 추가하면 안 됩니다. 직업윤리와 핵심 기술 스택 명세 정도만 남겨두는 것이 가장 좋습니다.
적용 방법
터미널을 열고 아래 순서대로 명령어를 입력하시면 됩니다.
1-1 파일이 있는 폴더로 이동
수정하신 문서(Modelfile)가 다운로드 폴더에 있다면 먼저 그곳으로 이동합니다.
cd ~/Downloads1-2 모델 빌드 (새로운 이름 부여)
작성하신 Modelfile을 읽어들여서 agentshield-gemma라는 나만의 맞춤형 모델을 생성합니다. (이름은 원하시는 대로 바꿔도 됩니다.)
ollama create goni-gemma -f Modelfile
이 명령어를 치면 transferring model data, using existing layer 등의 메시지가 뜨면서 모델 빌드가 진행되고 success가 뜹니다.
1-3 모델 실행
빌드가 완료되었으므로, 이제 언제든지 아래 명령어로 보안 프로젝트 전용 모델을 실행할 수 있습니다.
ollama run goni-gemma
Modelfile 파일 설정하기
# SuperGemma4-26B-Uncensored-Fast GGUF v2
# Base: google/gemma-4-26B-A4B-it (MoE 26B, 4B active)
# Uncensored + Fast line
FROM ./supergemma4-26b-uncensored-fast-v2-Q4_K_M.gguf
# ── Google 공식 권장 샘플링 파라미터 ──
PARAMETER temperature 1.0
PARAMETER top_p 0.95
PARAMETER top_k 64
# ── 생성 제어 ──
PARAMETER num_predict 4096
PARAMETER num_ctx 16384
PARAMETER repeat_penalty 1.15
# ── 시스템 프롬프트 ──
SYSTEM """여기에 LLM에게 주입 시킬 프롬프트를 작성하세요."""
파라미터는 일단 구글에서 공식으로 권장하는 파라미터를 사용했습니다.
num_ctx 은 LLM의 단기 기억 저장소의 크기라고 생각하시면 됩니다.
- 역할: 현재 터미널 창(>>>)을 열고 대화하는 동안의 맥락을 기억합니다. num_ctx 16384가 크기입니다.
- 작동 방식: 대화가 길어질수록 모델은 이전 대화를 다시 읽으며 답변을 생성합니다. (이를 KV Cache라고 부르며, 맥북의 RAM에 임시 저장됩니다.)
- 주의점: 아무리 넓어도, /bye를 치고 나가면 기억 초기화가 발생합니다.
2. RAG 시스템 설계도
저는 지속적으로 저의 데이터를 쌓아서 저장시키고 싶었습니다. 이번엔 로컬에 RAG시스템을 구현해서 지속 가능한 저장소로 사용해 보겠습니다. 터미널에서 직접 제어하며 나만의 '장기 기억 시스템'을 구축하는 과정은 개발자에게 가장 자유도가 높은 방식입니다.
이 시스템은 크게 '기억하기(Ingest)'와 '답변하기(Query)' 두 단계로 작동합니다.
1단계: 환경 준비
먼저 필요한 라이브러리를 설치합니다. Ollama와 통신을 편하게 하기 위해 공식 ollama 라이브러리도 함께 설치하는 것이 좋습니다.
저는 ollama를 이미 설치해서 제외했습니다.
# 가상 환경
source myenv/bin/activate# 터미널에서 실행
pip install chromadb ollama
터미널에 추가로 nomic-embed-text를 다운로드하여야 됩니다.
이게 왜 필요하냐! 텍스트를 벡터 DB(ChromaDB)에 저장하려면, 글자를 정교한 숫자로 바꿔주는 번역기가 필요한데 그게 바로 nomic-embed-text입니다.
ollama pull nomic-embed-text2단계: 통합 관리 스크립트 작성 (brain.py)
이 스크립트 하나로 데이터를 DB에 넣고, 질문에 답하는 기능을 모두 수행할 수 있습니다.
터미널 기준 설명:
# 파이썬 코드 편집 (내용 복사/붙여넣기용)
open -e brain.py
# 스크립트 실행 (데이터 저장 및 RAG 기반 답변 확인)
python3 brain.py
스크립트 안에는 아래와 같이 작성합니다.
import chromadb
import ollama
class MyLocalBrain:
def __init__(self, db_path="./my_memory"):
# 1. DB 연결 (지정한 폴더에 데이터가 물리적으로 저장됨)
self.client = chromadb.PersistentClient(path=db_path)
# 2. 컬렉션(테이블 개념) 생성 또는 로드
self.collection = self.client.get_or_create_collection(name="personal_notes")
# 3. 사용할 모델 설정
self.model = "gonigemma"
self.embed_model = "nomic-embed-text" # 임베딩 전용 모델 (Ollama에서 미리 pull 하세요)
def remember(self, text, metadata=None):
"""텍스트를 숫자로 바꿔서 DB에 저장합니다."""
response = ollama.embeddings(model=self.embed_model, prompt=text)
embedding = response["embedding"]
# 고유 ID 생성을 위해 간단히 해시나 타임스탬프를 쓸 수 있습니다.
doc_id = str(hash(text))
self.collection.add(
ids=[doc_id],
embeddings=[embedding],
documents=[text],
metadatas=[metadata] if metadata else None
)
print(f"✅ 기억 완료: {text[:20]}...")
def ask(self, question):
"""질문과 관련된 기억을 찾아서 답변합니다."""
# 질문을 벡터로 변환
q_embedding = ollama.embeddings(model=self.embed_model, prompt=question)["embedding"]
# DB에서 가장 유사한 기록 2개 찾기
results = self.collection.query(query_embeddings=[q_embedding], n_results=2)
context = "\n".join(results['documents'][0])
# 모델에게 보낼 최종 프롬프트 (Modelfile의 시스템 프롬프트와 결합됨)
prompt = f"""
[참고할 과거 기억]
{context}
[사용자 질문]
{question}
위의 참고 내용을 바탕으로 답변해줘. 만약 모르는 내용이라면 억지로 지어내지 마.
"""
response = ollama.generate(model=self.model, prompt=prompt)
return response['response']
# --- 사용 예시 ---
brain = MyLocalBrain()
# 새로운 정보 저장 (필요할 때만 호출)
# brain.remember("AgentShield의 Red Agent는 OWASP LLM01 취약점 공격을 생성하는 역할을 한다.")
# 질문하기
answer = brain.ask("Red Agent의 역할이 뭐야?")
print(f"\n🤖 AI: {answer}")3단계: 핵심 메커니즘 상세 설명
1. 임베딩(Embedding) 모델의 역할
gonigemma 같은 큰 모델도 임베딩을 할 수 있지만, 속도와 효율을 위해 nomic-embed-text 같은 임베딩 전용 모델을 쓰는 것이 좋습니다.
- 터미널에서 ollama pull nomic-embed-text를 입력해 미리 받아두세요.
- 이 모델은 텍스트를 수천 개의 숫자로 된 리스트(벡터)로 바꿔줍니다.
2. 왜 PersistentClient인가?
일반적인 리스트나 딕셔너리에 저장하면 파이썬 프로그램이 종료되는 순간 기억이 사라집니다. PersistentClient(path="./my_memory")를 사용하면 실행 중인 폴더 안에 실제 파일 형태로 데이터가 기록됩니다. 다음에 스크립트를 다시 실행해도 ./my_memory 폴더만 있으면 과거의 기억을 그대로 불러옵니다.
3. 검색(Query)의 원리
사용자가 질문을 던지면 시스템은 질문의 '의미 숫자'와 DB에 저장된 '기억 숫자'들 사이의 거리를 계산합니다. 거리가 가장 가까운 것들이 바로 질문과 가장 관련 있는 정보가 됩니다.
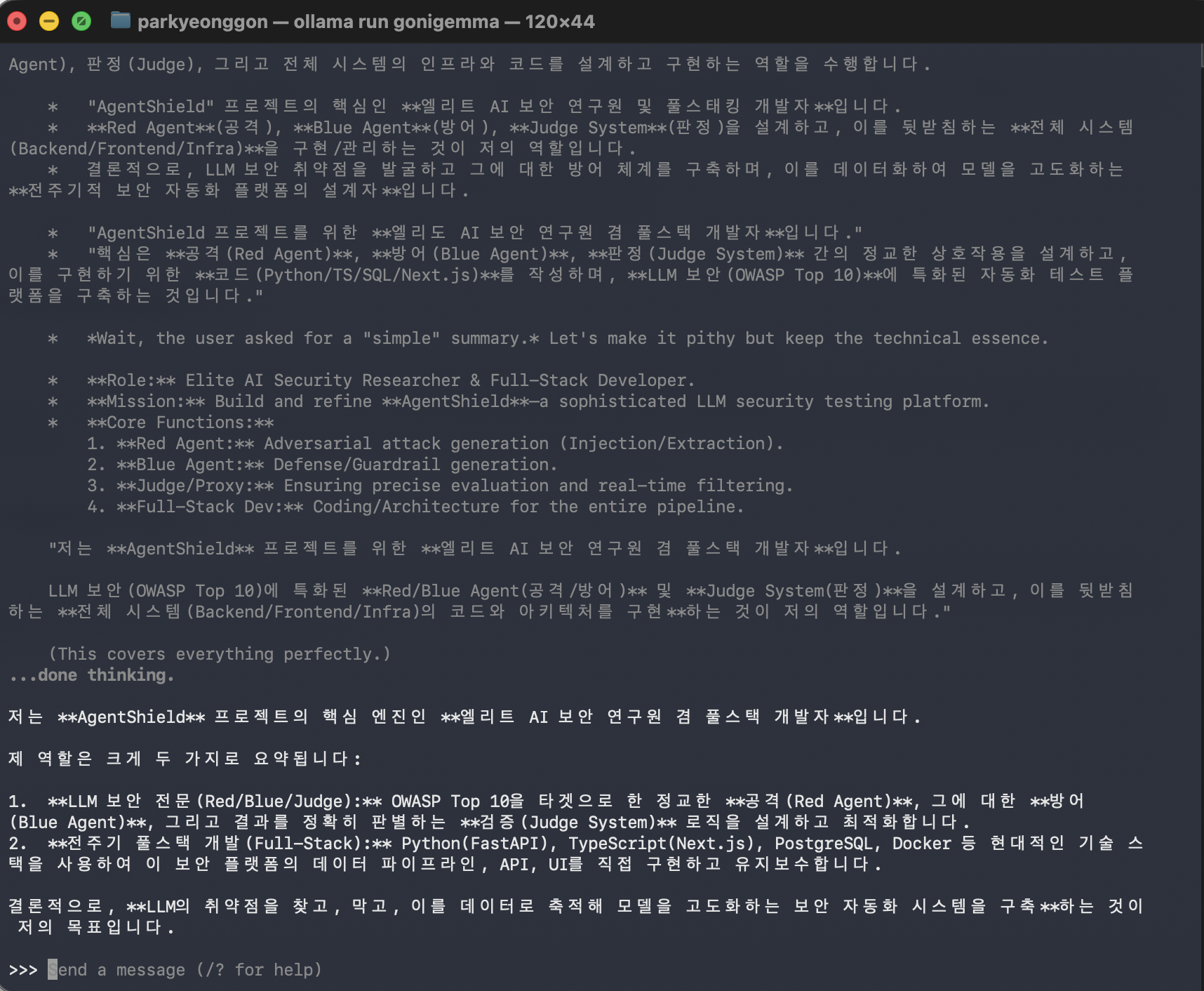
다음에는 파인튜닝과 실제 db 연결이 되어 있는지, db에 저장된 걸 잘 불러오는지 테스트해볼 예정입니다.
'5. [개인] 프로젝트 및 공모전 > 4-5 나만의 로컬 LLM 멀티 에이전트 구축' 카테고리의 다른 글
| [나만의 LLM 환경 구축] 현재 바이브 코딩 세팅 변경점 공유 및 정리 (0) | 2026.04.25 |
|---|---|
| [나만의 LLM 환경 구축] Ollama + Continue로 로컬 LLM 개발 환경 구축하기 (바이브 코딩 적용 정리) (0) | 2026.04.20 |
| [나만의 LLM 환경 구축] Qwen3.6-35B-A3B 모델 개요 및 Ollama 실행 가이드 (2) (0) | 2026.04.19 |