저번 블로그에 이어 벡터 데이터베이스 구축에 대한 정리 블로그를 작성합니다.
[RAG 시스템 구축] 벡터 데이터베이스부터 앙상블 리트리버까지 (1)
대형 언어 모델(LLM)의 성능을 극대화하고 최신 정보를 반영하기 위한 RAG(Retrieval-Augmented Generation) 시스템의 핵심 구성 요소인 벡터 데이터베이스, 청킹 전략, 그리고 리트리버 활용법을 정리한다.
pak1010pak.tistory.com
1. 환각 여부를 평가하는 RAG (Self-Reflective RAG)
단순히 문서를 검색하고 답변을 생성하는 것을 넘어, 검색된 문서가 질문과 관련이 있는지, 생성된 답변이 문서에 근거하고 있는지(환각 여부), 그리고 사용자의 질문을 완벽히 해결했는지를 스스로 평가하고 보완하는 고급 RAG 파이프라인이다. LangGraph를 활용하여 상태 기반의 워크플로우를 구축한다.

기본 설정 및 리트리버 준비
문서를 청킹하고 벡터 데이터베이스에 저장한 뒤, 리트리버와 LLM을 초기화한다. 질문 재작성과 답변 재생성의 최대 횟수도 제한하여 무한 루프를 방지한다.
from langchain_community.document_loaders import PyPDFLoader
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_chroma import Chroma
from langchain_experimental.text_splitter import SemanticChunker
PDF_PATH = "/content/AI브리프_3월_260303.pdf"
PERSIST_DIR = "./chroma_ai_brief"
LLM_MODEL = "gpt-5.4-2026-03-05"
EMBEDDING_MODEL = "text-embedding-3-small"
TOP_K = 3
MAX_REWRITE = 2
MAX_REGENERATE = 2
loader = PyPDFLoader(PDF_PATH)
pages = loader.load()
embeddings = OpenAIEmbeddings(model=EMBEDDING_MODEL)
text_splitter = SemanticChunker(embeddings)
docs = text_splitter.split_documents(pages)
vectorstore = Chroma.from_documents(
documents=docs,
embedding=embeddings,
persist_directory=PERSIST_DIR
)
retriever = vectorstore.as_retriever(search_kwargs={"k": TOP_K})
llm = ChatOpenAI(model=LLM_MODEL, temperature=0)
상태(State) 및 평가 모델(Pydantic) 정의
LangGraph에서 노드 간 전달될 상태 변수들과 LLM이 구조화된 출력(Structured Output)으로 평가 결과를 반환하도록 Pydantic 모델을 정의한다.
from typing import Literal, List
from langgraph.graph import MessagesState
from pydantic import BaseModel, Field
# 상태 정의
class State(MessagesState):
question: str # 원본 질문
rewritten_question: str # 개선된 질문
documents: List[str] # 검색된 문서 리스트
context: str # 문서 통합 문자열
generation: str # LLM 답변 결과
rewrite_count: int # 질문 재작성 횟수
regenerate_count: int # 답변 재생성 횟수
relevance_passed: bool # 문서 관련성 통과 여부
grounded_passed: bool # 답변 근거(환각) 통과 여부
answer_passed: bool # 질문 해결 통과 여부
need_retrieval: bool # 검색 필요 여부
route_label: str # 라우팅 라벨
final_status: str # 최종 상태
# 평가용 Pydantic 모델
class RetrievalNeedGrade(BaseModel):
binary_score: Literal['yes', 'no'] = Field(description="내부 문서 검색 필요 여부")
class RelevanceGrade(BaseModel):
binary_score: Literal['yes', 'no'] = Field(description="검색 문서와 질문의 관련성")
class GroundingGrade(BaseModel):
binary_score: Literal['yes', 'no'] = Field(description="답변의 문서 근거 여부")
class AnswerGrade(BaseModel):
binary_score: Literal['yes', 'no'] = Field(description="답변의 질문 해결 여부")
주요 노드(Node) 구성
각 단계별 동작을 수행할 함수들을 정의한다.
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import AIMessage
# 1. 내부 문서 검색 필요 여부 판단
def decide_need_retrieval(state: State):
question = state.get("question", "").strip()
if not question:
human_messages = [m for m in state['messages'] if m.type == 'human']
question = human_messages[-1].content.strip() if human_messages else ""
grader = llm.with_structured_output(RetrievalNeedGrade)
prompt = ChatPromptTemplate.from_messages([
("system", "사용자의 질문이 내부 PDF 문서 검색이 필요한지 판단하는 평가자입니다. yes 또는 no만 판단하세요."),
("human", "{question}")
])
score = (prompt | grader).invoke({"question": question})
need_retrieval = score.binary_score == "yes"
return {
"question": question,
"rewritten_question": question,
"need_retrieval": need_retrieval,
"route_label": "retrieval_needed" if need_retrieval else "no_retrieval_needed"
}
# 2. 내부 문서 검색 불필요 시 직접 답변
def direct_answer(state: State):
question = state['question']
prompt = ChatPromptTemplate.from_messages([
("system", "내부 문서 검색 없이 일반 지식으로 답변하세요. 모르면 모른다고 말하세요."),
("human", "{question}")
])
response = (prompt | llm).invoke({"question": question})
return {
"generation": response.content,
"final_status": "answered_without_retrieval",
"messages": [response],
"answer_passed": False,
"grounded_passed": False,
"relevance_passed": False
}
# 3. 문서 검색
def retrieve(state: State):
question = state.get("rewritten_question") or state.get("question", "")
retrieved_docs = retriever.invoke(question.strip())
doc_texts = [doc.page_content for doc in retrieved_docs]
context = "\n\n".join([f"[문서 {i+1}]\n{text}" for i, text in enumerate(doc_texts)])
return {
"documents": doc_texts,
"context": context,
"route_label": "retrieval_executed"
}
# 4. 검색 문서 관련성 평가
def grade_documents(state: State):
question = state['rewritten_question'] or state['question']
context = state['context']
if not context.strip():
return {"relevance_passed": False, "context": "", "documents": []}
grader = llm.with_structured_output(RelevanceGrade)
prompt = ChatPromptTemplate.from_messages([
("system", "검색된 문서가 사용자 질문과 관련 있는지 평가합니다. yes 또는 no만 판단하세요."),
("human", "[질문]\n{question}\n\n[검색 문서]\n{context}")
])
score = (prompt | grader).invoke({"question": question, "context": context})
return {"relevance_passed": score.binary_score == "yes"}
# 5. 사용자 쿼리 재작성
def transform_query(state: State):
question = state['rewritten_question'] or state.get("question", "")
rewrite_count = state.get("rewrite_count", 0)
prompt = ChatPromptTemplate.from_messages([
("system", "사용자의 원래 의미를 유지하면서 검색이 잘 되도록 더 명확하고 구체적인 질문으로 바꾸세요."),
("human", "원래 질문:\n{question}\n\n개선된 질문을 한국어로 작성하세요.")
])
better_question = (prompt | llm).invoke({"question": question}).content.strip()
return {
'rewritten_question': better_question,
'rewrite_count': rewrite_count + 1,
'route_label': 'query_rewritten'
}
# 6. 답변 생성
def generate(state: State):
question = state['question']
context = state['context']
if not context.strip():
answer = '관련 문서를 찾지 못해 정확히 답변하기 어렵습니다.'
return {'generation': answer, 'messages': [AIMessage(content=answer)], 'final_status': 'failed_no_context'}
prompt = ChatPromptTemplate.from_messages([
("system", "검색된 문서를 바탕으로 질문에 답하세요. 문서에 없는 내용은 추측하지 마세요.\n[검색 문서]\n{context}"),
("human", "{question}")
])
response = (prompt | llm).invoke({"question": question, "context": context})
return {"generation": response.content, "messages": [response]}
# 7. 환각 평가 (Grounding)
def grade_grounding(state: State):
context = state['context']
generation = state['generation']
grader = llm.with_structured_output(GroundingGrade)
prompt = ChatPromptTemplate.from_messages([
("system", "답변이 문서에 의해 뒷받침되면 yes, 지어냈거나 과도한 추론이면 no로 판단하세요."),
("human", "[검색 문서]\n{context}\n\n[답변]\n{generation}")
])
score = (prompt | grader).invoke({"context": context, "generation": generation})
return {"grounded_passed": score.binary_score == "yes"}
# 8. 답변 해결성 평가
def grade_answer(state: State):
question = state['question']
generation = state['generation']
grader = llm.with_structured_output(AnswerGrade)
prompt = ChatPromptTemplate.from_messages([
("system", "답변이 질문을 충분히 해결했으면 yes, 부분적으로 답했거나 빗나갔으면 no로 판단하세요."),
("human", "[질문]\n{question}\n\n[답변]\n{generation}")
])
score = (prompt | grader).invoke({"question": question, "generation": generation})
return {"answer_passed": score.binary_score == "yes"}
# 9. 재생성 및 유틸리티 노드들
def regenerate(state: State):
regenerate_count = state.get("regenerate_count", 0)
prompt = ChatPromptTemplate.from_messages([
("system", "검색 문서에 엄격히 근거해 다시 답변하세요. 문서에 없는 정보는 절대 추가하지 마세요.\n[검색 문서]\n{context}"),
("human", "{question}")
])
response = (prompt | llm).invoke({"question": state['question'], "context": state['context']})
return {
"generation": response.content,
"regenerate_count": regenerate_count + 1,
"messages": [response],
"route_label": "regenerated_after_grounding_fail"
}
def give_up(state: State):
answer = "관련 문서를 충분히 찾지 못해 정확한 답변을 제공하기 어렵습니다."
return {"generation": answer, "messages": [AIMessage(content=answer)], "final_status": "give_up_after_rewrite"}
def fail_grounding(state: State):
answer = "답변이 문서에 충분히 근거했다고 검증되지 않아 응답 생성을 중단합니다."
return {"generation": answer, "messages": [AIMessage(content=answer)], "final_status": "fail_grounding"}
def finalize_success(state: State):
return {"final_status": "success"}
워크플로우 그래프(LangGraph) 구축 및 분기 조건
평가 결과에 따라 노드의 흐름을 제어하는 조건부 라우팅 함수를 구성하고 그래프를 컴파일한다.
from langgraph.graph import StateGraph, START, END
def route_after_need_retrieval(state: State):
return "retrieve" if state['need_retrieval'] else "direct_answer"
def route_after_relevance(state: State):
if state.get("relevance_passed", False): return "generate"
if state.get("rewrite_count", 0) >= MAX_REWRITE: return "give_up"
return "transform_query"
def route_after_grounding(state: State):
if state.get("grounded_passed", False): return "grade_answer"
if state.get("regenerate_count", 0) >= MAX_REGENERATE: return "fail_grounding"
return "regenerate"
def route_after_answer(state: State):
if state.get("answer_passed", False): return "finalize_success"
if state.get("rewrite_count", 0) >= MAX_REWRITE: return "finalize_success"
return "transform_query"
graph_builder = StateGraph(State)
# 노드 추가
graph_builder.add_node("decide_need_retrieval", decide_need_retrieval)
graph_builder.add_node("direct_answer", direct_answer)
graph_builder.add_node("retrieve", retrieve)
graph_builder.add_node("grade_documents", grade_documents)
graph_builder.add_node("transform_query", transform_query)
graph_builder.add_node("generate", generate)
graph_builder.add_node("grade_grounding", grade_grounding)
graph_builder.add_node("grade_answer", grade_answer)
graph_builder.add_node("regenerate", regenerate)
graph_builder.add_node("give_up", give_up)
graph_builder.add_node("fail_grounding", fail_grounding)
graph_builder.add_node("finalize_success", finalize_success)
# 엣지 연결 (워크플로우 정의)
graph_builder.add_edge(START, "decide_need_retrieval")
graph_builder.add_conditional_edges("decide_need_retrieval", route_after_need_retrieval, {"retrieve": "retrieve", "direct_answer": "direct_answer"})
graph_builder.add_edge("direct_answer", END)
graph_builder.add_edge("retrieve", "grade_documents")
graph_builder.add_conditional_edges("grade_documents", route_after_relevance, {"generate": "generate", "transform_query": "transform_query", "give_up": "give_up"})
graph_builder.add_edge("transform_query", "retrieve")
graph_builder.add_edge("generate", "grade_grounding")
graph_builder.add_conditional_edges("grade_grounding", route_after_grounding, {"grade_answer": "grade_answer", "regenerate": "regenerate", "fail_grounding": "fail_grounding"})
graph_builder.add_edge("regenerate", "grade_grounding")
graph_builder.add_conditional_edges("grade_answer", route_after_answer, {"finalize_success": "finalize_success", "transform_query": "transform_query"})
graph_builder.add_edge("finalize_success", END)
graph_builder.add_edge("give_up", END)
graph_builder.add_edge("fail_grounding", END)
graph = graph_builder.compile()
2. 테스트 실행 코드
구축된 에이전트 시스템이 다양한 상황(일반 대화, 불명확한 질문, 문서 밖의 정보 요구 등)에서 견고하게 작동하는지 검증하는 테스트 코드이다.
from langchain_core.messages import HumanMessage
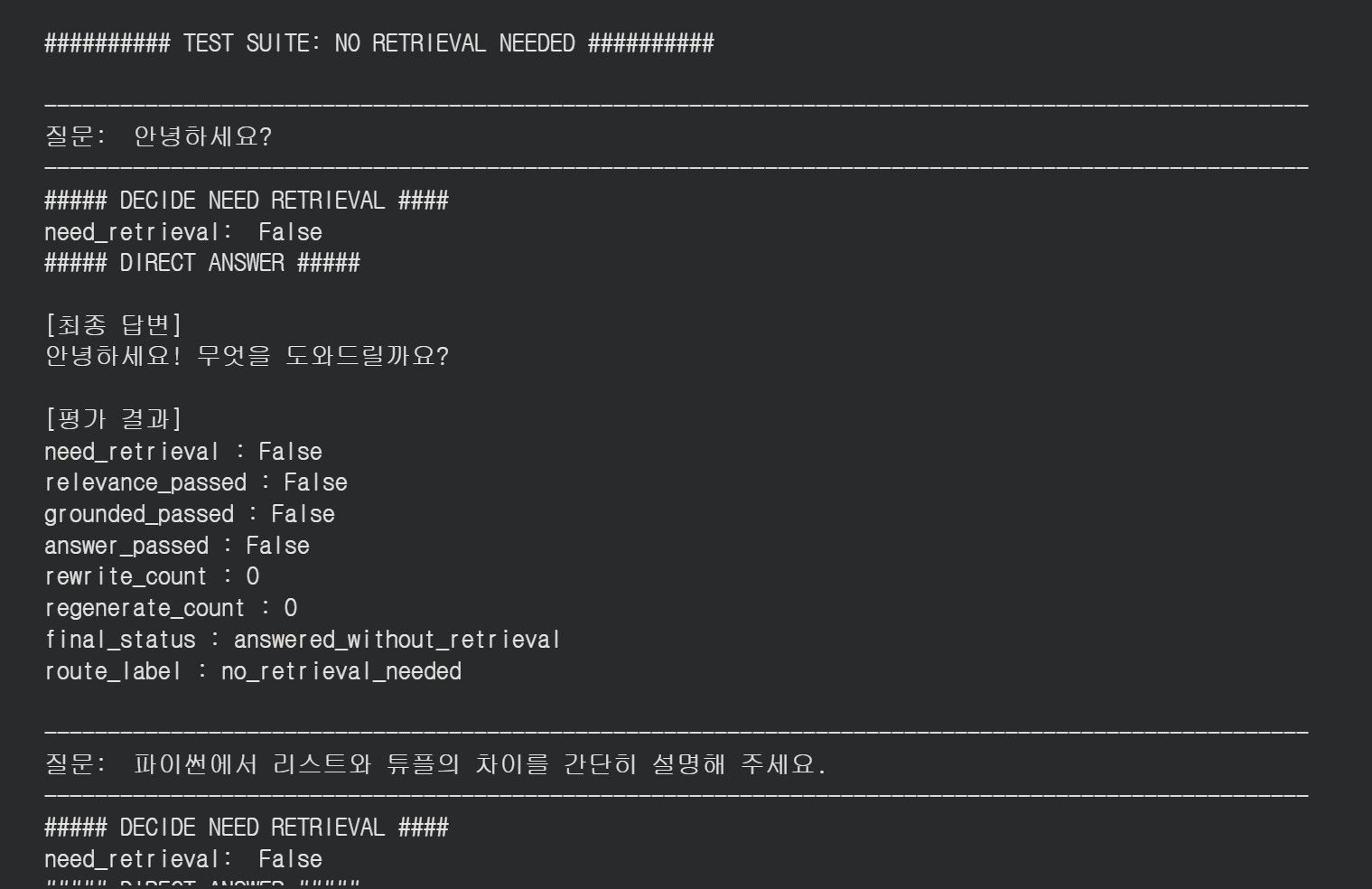
def run_rag_test(question: str):
print("\n" + "-" * 100)
print("질문: ", question)
inputs = {
"messages": [HumanMessage(content=question)],
"question": question,
"rewritten_question": question,
"documents": [],
"context": "",
"generation": "",
"rewrite_count": 0,
"regenerate_count": 0,
"relevance_passed": False,
"grounded_passed": False,
"answer_passed": False,
"need_retrieval": False,
"route_label": "",
"final_status": ""
}
result = graph.invoke(inputs)
print("\n[최종 답변]")
print(result.get("generation", ""))
print("\n[평가 결과]")
print(f"need_retrieval: {result.get('need_retrieval')}")
print(f"relevance_passed: {result.get('relevance_passed')}")
print(f"grounded_passed: {result.get('grounded_passed')}")
print(f"answer_passed: {result.get('answer_passed')}")
print(f"rewrite_count: {result.get('rewrite_count')}")
print(f"regenerate_count: {result.get('regenerate_count')}")
print(f"final_status: {result.get('final_status')}")
return result
def run_test_suite(test_name: str, questions: list[str]):
print(f"\n\n########## TEST SUITE: {test_name} ##########")
results = []
for q in questions:
result = run_rag_test(q)
results.append(result)
return results
# 테스트 케이스 정의 및 실행
no_retrieval_questions = [
"안녕하세요?",
"파이썬에서 리스트와 튜플의 차이를 간단히 설명해 주세요.",
"오늘 기분이 좀 우울한데 한 마디 해주세요."
]
retrieval_needed_questions = [
"앤트로픽과 미국 국방부의 AI 가드레일 갈등 핵심 내용을 요약해 주세요.",
"미국 노동부 AI 리터러시 프레임워크의 핵심 내용을 설명해 주세요."
]
rewrite_test_questions = [
"가드레일 갈등 뭐임?",
"마이아 200 장점"
]
answer_resolution_questions = [
"영국의 2026 국제 AI 안전 보고서가 제시한 위험 범주를 설명해 주세요.",
"로버트 라이시는 AI와 불평등 문제를 어떻게 설명하나요?"
]
grounding_stress_questions = [
"Claude Opus 4.6의 정확한 API 가격표를 알려주세요.",
"프리즘의 월 구독료와 기업용 요금제를 자세하게 알려주세요."
]
# 각 스위트 실행
run_test_suite("NO RETRIEVAL NEEDED", no_retrieval_questions)
run_test_suite("RETRIEVAL NEEDED", retrieval_needed_questions)
run_test_suite("QUERY REWRITE", rewrite_test_questions)
run_test_suite("ANSWER RESOLUTION", answer_resolution_questions)
run_test_suite("GROUNDING STRESS", grounding_stress_questions)출력(답변) 예시
'개념 정리 step2 > AI Agent' 카테고리의 다른 글
| [SQL RAG] LangChain과 LangGraph를 활용한 지능형 데이터베이스 질의 에이전트 구축(쿼리문 RAG) (0) | 2026.04.02 |
|---|---|
| [RAG 시스템 구축] 벡터 데이터베이스부터 앙상블 리트리버까지 (1) (0) | 2026.03.31 |
| [LangGraph] LLM 도구 사용법 (Tool Calling & Agents) (5) (0) | 2026.03.23 |
| [AI Agent] "Tool Calling Agent의 개념"과 "Tavily"를 활용한 웹 검색 챗봇 구현 (4) (0) | 2026.03.20 |
| [LangGraph] 상태 업데이트 및 워크플로우 제어 (3) (0) | 2026.03.19 |