
2-Stage Pipeline의 이론적 기반, 실험 결과, 그리고 공모전 회고
아래 블로그 상세 분석 개인 연구 블로그 1편도 있습니다.
[공모전] Vision 시각화 검증 상세 분석 "개인 연구용" 블로그
안녕하세요!!오늘은 지금 데이콘에서 진행중인 공모전에 대해서 제 주관적인 생각을 아주 많이 넣은(?) 연구용 블로그를 작성해보겠습니다. 이미 상위 랭킹에 속하긴 했지만 순위를 더 좁히고
pak1010pak.tistory.com
코랩 파일만 11번 버전 파일 생성, 로컬로도 몇 개의 파일들이 생성됐는 지 모르겠다. 처음엔 동기들과 가볍게 나가기로 했기에 욕심을 안 부렸지만 내 성격이 그게 안 되었나 보다. 오늘 결과 발표가 나왔는데 아쉽게 상위4% - 16등(전체 851명 중)에 머물렀지만, 내가 열심히 공부하고 분석한 내용에 대해서 정리하고자 한다.

1. 실험 동기
문제의 핵심
구조물 안정성 예측은 이미지 내 구조물의 물리적 형태를 보고 "이것이 무너질 것인가?"를 판단하는 과제다. 입력은 같은 구조물을 두 시점(front, top)에서 촬영한 이미지 쌍이다.
v10까지의 관찰 -- v10, v11은 코랩 버전을 뜻한다.
| 모델 | 강점 | 약점 | Dev LL |
|---|---|---|---|
| DINOv2-Large | 구조물을 "물체"로 인식하는 능력 탁월 (spatial features) | 안정/불안정의 미세한 차이 구분 부족 | ~0.002 (OOF) |
| EVA-Giant | 세밀한 시각적 패턴으로 분류 정밀도 높음 (fine-grained) | 배경(체커보드 바닥, 하늘)에 의존하여 오분류 | ~0.006 |
v10에서 DINOv2 + EVA를 독립적으로 학습 후 앙상블(XGBoost stacking)한 결과:
- OOF Dev LogLoss = 0.001792 (놀라운 성능)
- LB = 0.0476 (심각한 괴리)
Dev-Test 갭 원인 진단
"Dev에선 완벽한데 Test에선 왜 나빠지는가?"
가설: EVA가 배경 텍스처(체커보드 패턴, 조명 각도)를 shortcut으로 학습한다? Dev와 Train은 같은 렌더링 엔진에서 유사한 배경을 공유하지만, Test는 미세하게 다른 배경 분포를 가질 수 있다?!
그래서...DINOv2의 attention으로 배경을 제거하면 EVA가 순수한 구조물 형태만 보게 되려나...?
v11의 핵심 발상
"DINO는 객체를 잘 찾고, EVA는 잘 분류한다.
그러면 DINO가 배경을 날려주고, EVA가 구조물만 보면?"
v10: DINOv2(전체 이미지) + EVA(전체 이미지) → Meta-Learner → 예측
v11: DINOv2(전체 이미지) → Attention Mask → EVA(마스크 이미지) → 예측
↑ 배경 제거 전문 ↑ 구조물 분석 전문2. Vision Transformer가 이미지를 보는 방식
패치 토큰화 (Patch Tokenization)
ViT는 이미지를 격자(grid)로 분할하여 각 조각(patch)을 하나의 "토큰"으로 취급한다.
$$
\text{Image} \in \mathbb{R}^{H \times W \times 3} \xrightarrow{\text{patch}} {p_1, p_2, \ldots, p_N}, \quad N = \frac{H}{P} \times \frac{W}{P}
$$
여기서 $P$는 패치 크기. 이 대회에서 사용한 모델들은 모두 $P = 14$:
| 모델 | 입력 크기 | 패치 크기 | 그리드 | 패치 수 |
|---|---|---|---|---|
| DINOv2-Large | 336×336 | 14×14 | 24×24 | 576 |
| EVA-Giant | 336×336 | 14×14 | 24×24 | 576 |
Self-Attention 메커니즘
각 레이어에서 모든 토큰들이 서로를 참조(attend)한다:
$$
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V
$$
여기서:
- $Q = XW_Q$ (Query: "나는 무엇을 찾고 있는가?")
- $K = XW_K$ (Key: "나는 무엇을 제공하는가?")
- $V = XW_V$ (Value: "내 실제 정보는 무엇인가?")
- $d_k$ = head dimension (스케일링 팩터)
CLS 토큰의 역할
ViT에는 입력 패치 외에 학습 가능한 [CLS] 토큰이 추가된다. 이 토큰은 모든 패치를 attend하면서 이미지 전체의 요약 표현을 축적한다:
$$
\text{CLS}_{\text{output}} = \text{Attention}(\text{CLS}_Q, \text{AllPatches}_K, \text{AllPatches}_V)
$$
최종 분류는 이 CLS 토큰의 출력에 기반한다. CLS→patch attention 가중치는 곧 "모델이 이미지의 어디를 보는가"를 의미한다.
DINOv2의 Register Token
DINOv2-reg4는 CLS 외에 4개의 register token을 추가로 사용한다:
$$
\text{Tokens} = [\text{CLS}, \text{REG}1, \text{REG}_2, \text{REG}_3, \text{REG}_4, p_1, p_2, \ldots, p{576}]
$$
Register token은 attention 계산에서 artifact를 흡수하는 버퍼 역할을 하며, CLS→patch attention을 추출할 때 반드시 건너뛰어야 한다(총 581개 중 앞 5개 = prefix).
3. DINOv2: Self-Supervised Spatial Expert
Self-Supervised 학습의 본질
DINOv2는 라벨 없이 1.42억장의 이미지에서 학습되었다. 핵심 원리는 자기 증류(self-distillation):
$$
\mathcal{L}{\text{DINO}} = -\sum{s \in \text{student}} \sum_{t \in \text{teacher}} p_t \log p_s
$$
- Teacher: 과거 가중치의 지수 이동 평균 (momentum update)
- Student: 현재 모델
- Multi-crop: 동일 이미지를 다양한 크기로 crop → 같은 대상에 대해 일관된 표현 학습
이 학습 방식의 결과, DINOv2는 명시적 지도 없이도 객체의 경계를 자연스럽게 파악한다.
DINOv2의 Attention이 특별한 이유
Supervised 학습(예: ImageNet 1000-class 분류)으로 학습된 ViT는 분류에 유리한 "대표적 텍스처"에 attention을 집중한다. 반면 DINOv2의 self-supervised 학습은:
- 전경/배경 분리: 같은 사물의 다양한 crop을 일관되게 인코딩해야 하므로, 배경을 무시하고 전경 객체에 집중하는 표현을 자연스럽게 학습
- 공간 구조 이해: 객체의 윤곽, 부품 간 관계를 인코딩
- 범용 시각적 의미: 특정 태스크에 편향되지 않은 "순수한" 시각적 특징
이것이 v11에서 DINOv2를 "배경 제거기"로 활용할 수 있는 이론적 근거다.
DINOv2 + CrossViewFusion Head
이 대회에서 DINOv2는 cross_attn head와 결합됐다:
Front View → DINOv2 Backbone → Patch Tokens (576, 1024) ──┐
├→ CrossViewFusion → Classification
Top View → DINOv2 Backbone → Patch Tokens (576, 1024) ──┘
CrossViewFusion 구조:
# 학습 가능한 [CLS] → 두 뷰의 패치 토큰 1152개에 attend
tokens = [cls_token, front_patches, top_patches] # (1 + 576 + 576, D)
output = TransformerEncoder(tokens, num_layers=4, num_heads=8)
logits = MLP(output[0]) # CLS 토큰 → 512 → 256 → 2이 구조가 효과적인 이유: "정면에서 보이는 기둥이 위에서는 기울어져 있다"는 3D 공간적 추론을 패치 레벨에서 수행할 수 있다.
v11에서의 DINOv2 활용: Attention Masking Engine
v11에서 DINOv2는 분류기가 아닌 "배경 제거기"로 사용된다. 이전 v10에서 finetuned된 DINOv2 가중치를 로드하여 attention을 추출한다.
Attention 추출 과정
- 마지막 4개 레이어의 CLS→patch attention을 추출 (multi-layer 평균으로 robustness 확보)
$$
\text{attn}l = \text{softmax}\left(\frac{q{\text{CLS}}^{(l)} \cdot K_{\text{patches}}^{(l)T}}{\sqrt{d_k}}\right) \in \mathbb{R}^{N_{\text{patches}}}
$$
- Multi-head 평균 (각 레이어당 16개 head):
$$
\bar{a}l = \frac{1}{H} \sum{h=1}^{H} \text{attn}_{l,h}
$$
- Multi-layer 평균:
$$
\text{heatmap} = \frac{1}{L} \sum_{l=1}^{L} \bar{a}_l \in \mathbb{R}^{24 \times 24}
$$
- Otsu 이진화 → morphological post-processing → binary mask
$$
\text{mask}(x, y) = \begin{cases} 1 & \text{heatmap}(x,y) > \tau_{\text{Otsu}} \text{ (구조물)} \ 0 & \text{otherwise (배경)} \end{cases}
$$
- 마스크 적용:
image[mask == 0] = (0, 0, 0)(배경 → 검은색)
Otsu Thresholding이 효과적인 이유
Otsu는 히스토그램의 bimodal 분포를 가정하여 전경/배경을 자동 분리한다:
$$
\tau^* = \arg\min_\tau \left[ w_0(\tau) \sigma_0^2(\tau) + w_1(\tau) \sigma_1^2(\tau) \right]
$$
DINOv2의 attention heatmap은 구조물(높은 attention)과 배경(낮은 attention)으로 자연스럽게 bimodal 분포를 형성하므로, Otsu가 잘 작동한다.
4. EVA-Giant: Supervised Fine-Grained Expert
EVA 사전학습 경로:
- Masked Image Modeling (MIM) — CLIP feature를 타겟으로 대규모 이미지에서 self-supervised 학습
- ImageNet-22K 분류 fine-tuning
- ImageNet-1K 분류 fine-tuning
이 3단계 학습 덕분에 EVA는 범용 시각 표현과 분류 정밀도를 모두 갖추고 있다.
EVA의 Attention 특성
EVA는 supervised 학습으로 fine-tuned되었기 때문에, attention이 분류에 도움되는 영역에 집중한다:
- 장점: "이 각도의 기울어짐 = unstable"이라는 직접적 판별 패턴 포착
- 단점: 배경 텍스처도 분류 단서로 사용 → 학습 데이터와 다른 배경에서 성능 저하
이것이 v10에서 관찰된 "Dev=완벽, Test=나쁨" 현상의 원인이다.
EVA + Simple Head
EVA는 1.0B 파라미터로 자체 표현력이 충분하므로, 가벼운 simple head를 사용:
Front View → EVA Backbone → CLS token (1408-dim) ──┐
├→ Concat → BN → 512 → 256 → 2
Top View → EVA Backbone → CLS token (1408-dim) ──┘cross_attn head 대신 simple head를 사용하는 이유:
- EVA 자체가 이미 깊은 attention 레이어(40 blocks)를 통해 충분한 표현을 학습
- 추가적인 cross-attention 레이어는 1.0B 위에 또 파라미터를 쌓게 되어 과적합 위험 증가
- Simple concat + MLP가 오히려 regularization 효과
Layer-wise Learning Rate Decay
두 모델 모두 LLRD를 사용하지만, 감쇠율이 다르다:
$$
\text{lr}{\text{layer } i} = \text{lr}{\text{base}} \times d^{(N-1-i)}
$$
| 모델 | $d$ (layer_decay) | 이유 |
|---|---|---|
| DINOv2 | 0.75 (공격적) | Self-supervised 사전학습의 하위 레이어는 매우 범용적 → 거의 고정 |
| EVA | 0.9 (완만) | Supervised 사전학습이므로 전 레이어가 비교적 고르게 유용 |
DINOv2에서 layer_decay=0.75일 때, 24개 블록 중:
- Block 0 (최하위): $\text{lr} \times 0.75^{23} \approx \text{lr} \times 0.0013$ (거의 frozen)
- Block 12 (중간): $\text{lr} \times 0.75^{11} \approx \text{lr} \times 0.042$
- Block 23 (최상위): $\text{lr} \times 0.75^{0} = \text{lr}$ (전체 학습률)
5. v11 아키텍처
전체 파이프라인
Phase 1: DINOv2 Attention Masking + EVA Training
① DINOv2 (finetuned) Attention 추출
└── CLS→Patch attention (last 4 layers avg)
└── Otsu threshold + morphology → Binary Mask
└── 이미지 배경 제거 (검은색)
② EVA-Giant가 마스크된 이미지로 5-fold CV 학습
└── 배경 없이 순수 구조물 형태만 학습
└── 체커보드 과적합 원천 차단
Phase 2: Curriculum Learning (원본 적응)
③ 원본 이미지 복원 (data.zip 재해제)
④ Phase 1 가중치에서 이어서 학습 (init_from_best)
└── 극히 낮은 LR (bb: 1e-6, head: 1e-5) × 3 epochs
└── 실제 테스트 이미지(원본)와의 도메인 갭 제거
Phase 1 설정
EVA_CONFIG = {
"backbone": "eva_giant",
"epochs": 30,
"patience": 15,
"head_lr": 1e-4,
"bb_lr": 1e-5,
"weight_decay": 0.05,
"drop_rate": 0.3,
"layer_decay": 0.9,
"warmup_epochs": 2,
"head_type": "simple",
"scheduler": "cosine",
"batch_size": 16,
}Phase 2 설정
EVA_PHASE2_CONFIG = {
"backbone": "eva_giant",
"epochs": 3, # 짧게! Phase 1 표현 보존이 핵심
"patience": 3,
"head_lr": 1e-5, # Phase 1의 1/10
"bb_lr": 1e-6, # Phase 1의 1/10 — 거의 freeze 수준
"layer_decay": 0.95, # 더 균일하게 (이미 잘 학습됨)
"warmup_epochs": 0, # 이미 수렴 상태
...
}DINOv2 마스킹 설정
MASK_IMG_SIZE = 336 # 336/14 = 24 (깔끔한 패치 그리드)
N_ATTN_LAYERS = 4 # 마지막 4개 레이어 평균
MASK_DILATE_ITER = 2 # 마스크 팽창 (구조물 경계 포함)
MASK_KERNEL_SIZE = 7
BG_FILL = (0, 0, 0) # 배경 → 검은색6. Phase 2: Curriculum Learning
Curriculum Learning (Bengio et al., 2009)은 "쉬운 것부터 어려운 것으로" 학습 순서를 조정하는 전략이다. v11에서 이를 변형했다.
Phase 1에서 마스크 이미지로만 학습하면:
- 장점: 배경 shortcut 학습 방지
- 한계: 테스트 이미지는 원본(배경 포함) → 도메인 갭 발생
Phase 2에서 극히 낮은 LR로 원본 이미지에 적응하면:
- Phase 1에서 학습한 "구조물 중심 표현"은 대부분 보존
- 원본 이미지의 색상/조명/질감 분포에 미세 적응
- 단 3 epoch만 학습하여 배경 shortcut 재학습 방지
7. 실험 결과 심층 분석
Phase 1: 5-Fold 학습 곡선
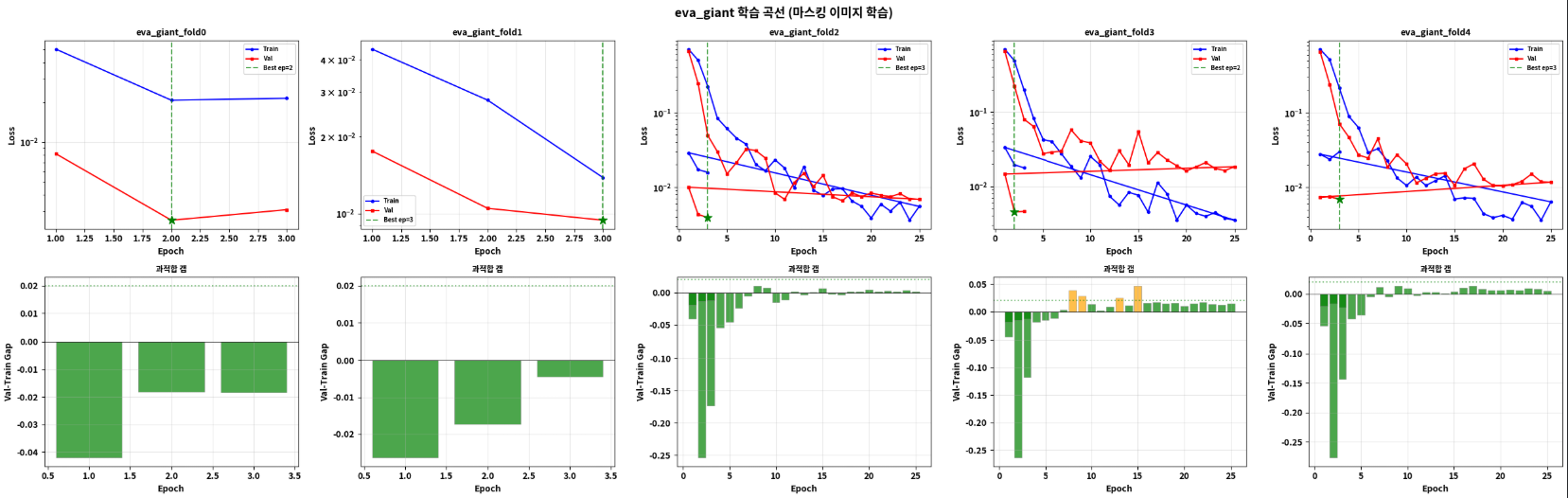
================================================================================
Fold Best Ep Val Loss Train Gap
================================================================================
eva_giant_fold0 2 0.0025659 0.0206779 -0.0181 OK
eva_giant_fold1 3 0.0094153 0.0138250 -0.0044 OK
eva_giant_fold2 3 0.0039454 0.0158015 -0.0119 OK
eva_giant_fold3 2 0.0045135 0.0194650 -0.0150 OK
eva_giant_fold4 3 0.0069069 0.0300605 -0.0232 OK
평균 과적합 갭: -0.0145
[v] 양호음수 갭(Val < Train)의 의미:
- Train에는 Dropout(0.3), Augmentation이 적용되어 loss가 높아짐
- Val은 clean inference → loss가 낮음
- 이는 과적합이 아닌 정규화 효과가 잘 작동 중임을 의미
Fold간 편차 분석:
- Fold 0 (Val=0.0026) vs Fold 1 (Val=0.0094): ~3.6배 차이
- 이는 100개 Dev 데이터의 fold 분할에 따른 자연스러운 변동
- 앙상블로 이 편차를 완화
Phase 1 → Phase 2 비교
Dev LL Acc Unstable Acc Stable Acc
Phase 1 (마스크) 0.133277 0.9300 0.8654 1.0000
Phase 2 (원본) 0.018457 1.0000 1.0000 1.0000
Phase 2 효과: -0.114820 (대폭 개선)핵심 관찰:
- Phase 1(마스크)만으로는 Dev LL=0.133 → 원본 이미지에서 성능 저하 (도메인 갭)
- Phase 2 후 Dev LL=0.018 → 원본 적응 성공
- 단 3 epoch의 추가 학습으로 7.2배 개선
Phase 1의 Unstable Acc = 0.8654가 낮은 이유:
마스크 이미지로 학습한 모델이 원본(배경 있는) Dev를 볼 때, 배경의 존재가 혼란을 야기. 특히 unstable 샘플 중 일부는 구조물의 미세한 기울기가 배경 제거로 인해 context를 잃음.
Fold별 상세 성능 (Phase 2 후)
Fold Split LogLoss Accuracy Unstable_Acc Stable_Acc
0 train 0.0022357 1.0000 1.0000 1.0000
0 dev 0.0409784 0.9800 0.9615 1.0000
1 train 0.0021484 1.0000 1.0000 1.0000
1 dev 0.0247851 0.9900 0.9808 1.0000
2 train 0.0022832 1.0000 1.0000 1.0000
2 dev 0.0132099 1.0000 1.0000 1.0000
3 train 0.0028747 1.0000 1.0000 1.0000
3 dev 0.0121686 1.0000 1.0000 1.0000
4 train 0.0033266 1.0000 1.0000 1.0000
4 dev 0.0168376 1.0000 1.0000 1.0000Fold 0이 유독 나쁜 이유:
- Dev LL = 0.041 (fold 3의 0.012 대비 3.4배)
- Unstable Acc = 0.9615 (다른 fold는 1.0)
- 원인: Fold 0의 validation split에 "경계선 샘플"이 집중
과적합 갭:
- 평균 Train LL: 0.00258
- 평균 Dev LL: 0.02160
- 갭: 0.019 → "약간의 과적합" 수준

앙상블 통계
EVA (Phase 2) 5-Fold 앙상블: Dev LL = 0.018457, Acc = 1.0000
확률 분포:
Stable 샘플: mean P(unstable) = 0.015062 (이상적: ≈0)
Unstable 샘플: mean P(unstable) = 0.981257 (이상적: ≈1)
Fold간 std: 0.010655 (낮음 = 일관적)
Confusion Matrix (Dev):

Predicted
Stable Unstable
True Stable 48 0 ← FP = 0 (완벽)
True Unstable 0 52 ← FN = 0 (완벽)
Accuracy = 100/100 = 1.0000
Dev에서 완벽한 분류. 하지만 이것이 곧 Test에서도 완벽함을 보장하지는 않는다 — 이것이 이 대회의 핵심 challenge였다.
8. 시각화 분석
EVA Attention Rollout — 모델이 실제로 보는 것
Attention Rollout 계산:
$$
\hat{A} = \prod_{l=1}^{L} \left( 0.5 \cdot \bar{A}_l + 0.5 \cdot I \right)
$$
여기서 $\bar{A}_l$은 레이어 $l$의 multi-head 평균 attention, $I$는 identity matrix (residual connection 반영). CLS 행을 추출하면 각 패치에 대한 "누적 attention"을 얻는다.
UNSTABLE 샘플 (높은 확신, P≈0.999)
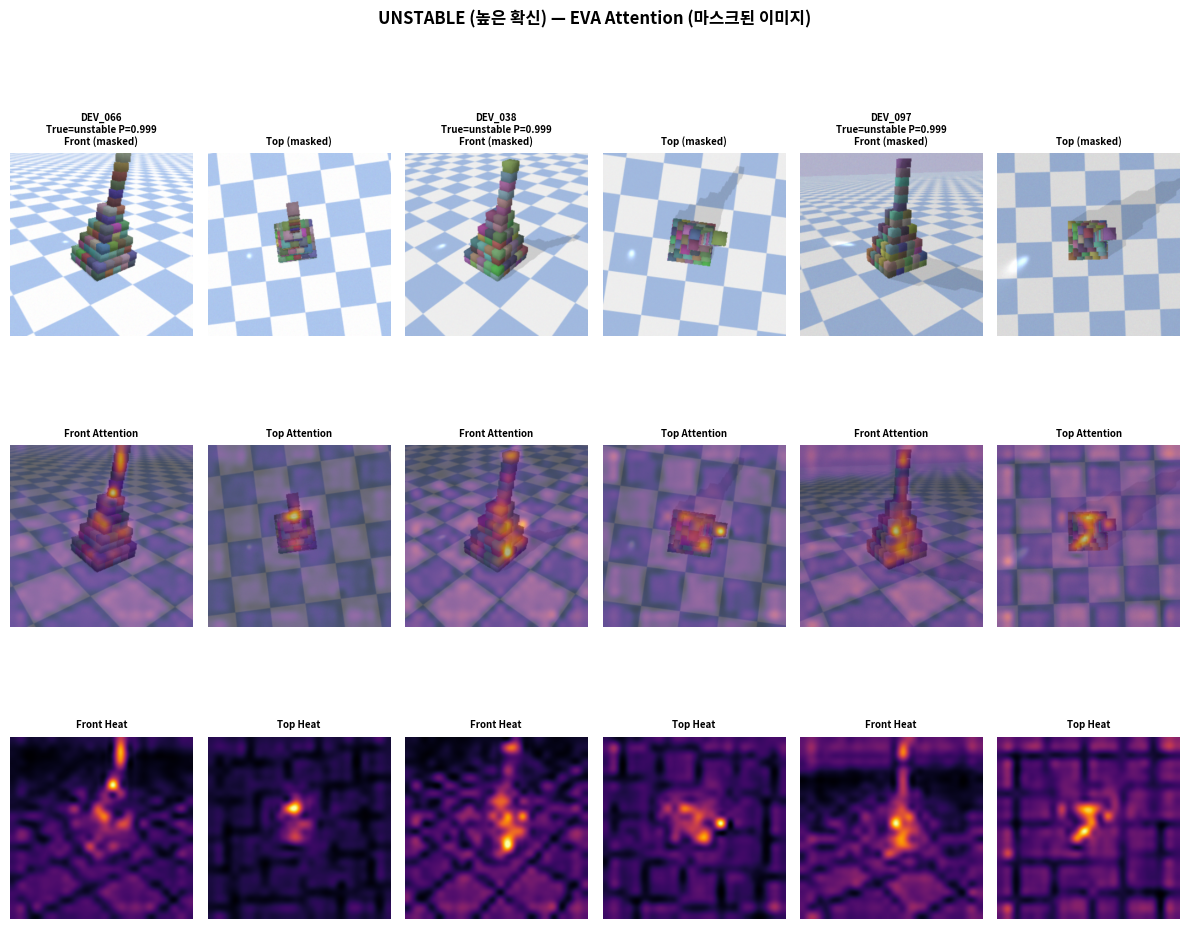
- EVA는 구조물의 상단 (꼭대기 블록들)에 강한 attention 집중
- 특히 불안정한 구조의 "꺾임점", "기울어진 블록"에 heatmap 밝기 최고
- 배경(검은색 영역)에는 거의 attention 없음 → 마스킹 성공
BORDERLINE 샘플 (불확실, P≈0.3~0.15)

- Attention이 구조물 전체에 분산됨 (특정 "위험 부위" 미발견)
- DEV_030 (P=0.337): 키가 크고 가늘지만 실제로는 unstable → 모델 혼란
- DEV_019 (P=0.064): 낮고 넓은 구조물 → stable로 자신 있게 판단
STABLE 샘플 (높은 확신, P≈0.001)
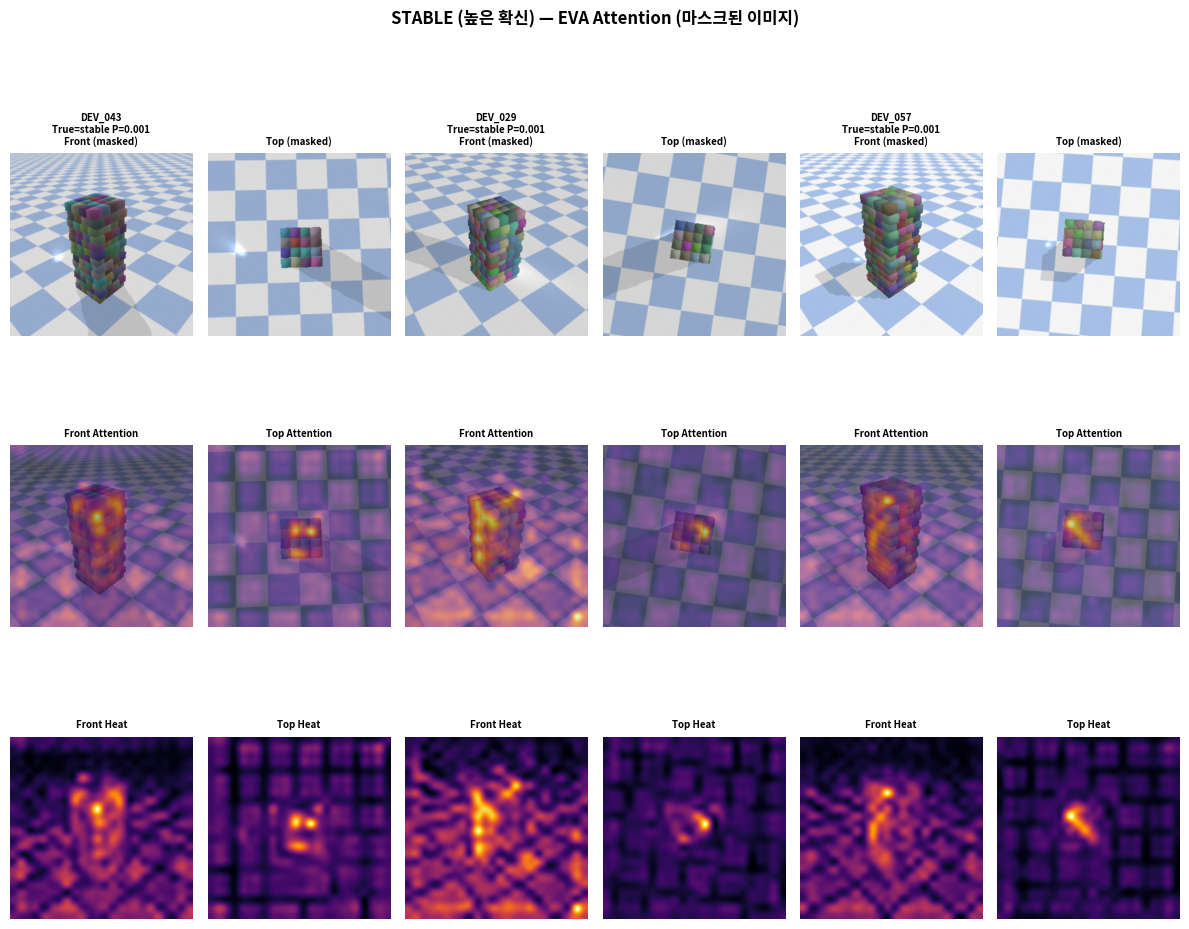
- Attention이 구조물의 넓은 기반부에 고르게 분포
- "기울어짐"이나 "꺾임" 감지 없음 → confident stable
시각화 이미지와 분석
EVA는 마스크 이미지에서 구조물의 기하학적 불균형 패턴를 학습했다:
- 상단 집중 attention → "꼭대기가 불안정하다" 신호
- 균일 분포 attention → "안정적 구조" 신호
- 이 패턴은 배경과 무관 → 일반화 가능성 높음
9. 개선 가능성 — 시간이 더 있었다면
1. DINOv2 마스킹 품질 개선 (가장 큰 병목)
문제: v10에서 finetuned된 DINOv2에 과적합이 섞여있었다. 일부 fold의 DINOv2가 배경 텍스처에도 attention을 보내고 있었을 가능성. v11에서는 fold 0의 DINOv2 하나만 마스킹에 사용 — 이 fold의 attention 품질이 전체 파이프라인을 좌우한다.
- 5개 fold의 DINOv2 attention을 앙상블하여 더 robust한 마스크 생성
- Attention threshold를 Otsu 대신 적응적 threshold (percentile 기반) 사용
- 마스크 품질 검증을 시각적으로 충분히 수행 (시간 부족으로 일부만 확인)
- DINOv2 pretrained (ImageNet 가중치)로 마스크 생성 시도 — finetuned보다 더 범용적일 수 있음
2. EVA 학습 설정 최적화 (LR 조정)
문제: Phase 1의 LR(bb=1e-5, head=1e-4)은 v10 설정을 그대로 사용. 마스크 이미지는 원본과 분포가 다르므로 별도 최적화가 필요했다.
- Phase 1 LR sweep: bb_lr ∈ {5e-6, 1e-5, 2e-5}, head_lr ∈ {5e-5, 1e-4, 2e-4}
- Phase 2 LR 및 epoch 수 최적화: 3 epoch이 최적인지 검증 필요
- Warmup 전략: Phase 2에서 warmup=0이 최적인지 (미세 warmup이 더 도움될 수 있음)
- Cosine schedule 대신 constant LR 시도 (3 epoch에서는 cosine이 의미 없을 수 있음)
3. 마스킹 전략 다양화
- Soft masking: 배경을 완전히 검은색으로 하는 대신, attention 가중치에 비례하여 blur 처리
$$\text{masked_img} = \text{img} \odot \alpha + \text{blur}(\text{img}) \odot (1-\alpha), \quad \alpha = \text{attention_heatmap}$$ - Multi-threshold: 0.3, 0.5, 0.7 threshold로 3가지 마스크 → TTA처럼 앙상블
- 배경 대체: 검은색 대신 균일한 회색(128, 128, 128) → ImageNet 사전학습 분포에 더 가까울 수 있음
4. 2-Stage 실험 순서 최적화
v10의 Meta-learner 접근과 v11의 Masking 접근을 결합:
Option A: DINOv2 mask → EVA (mask) + DINOv2 (원본) → Meta-learner
Option B: DINOv2 mask → EVA (mask, Phase 1+2) + EVA (원본, 별도) → 가중 앙상블
Option C: 여러 DINOv2 fold의 마스크 앙상블 → EVA 학습5. 데이터 증강 강화
마스크 이미지 특화 증강:
- 마스크 경계에 random erosion/dilation (마스크 경계 다양성)
- 마스크된 영역 내에서만 ColorJitter (구조물에만 색상 변형)
- 구조물 위치 random shift (마스크 후 구조물이 항상 중앙에 있지 않도록)
주관적 연구 내용 요약
이 방법론은 이론적으로 올바른 방향이었고, Dev-Test 갭이 v10 대비 줄어든 것이 그 증거다. 시간이 더 있었다면,
- DINOv2 마스크 품질을 충분히 검증하고,
- EVA LR을 마스크 이미지에 맞게 최적화하고,
- 여러 마스킹 전략을 비교했다면 더 일반화 성능이 좋은 모델이 완성되지 않았을까 싶습니다.
"어디를 볼 것인가"(DINOv2)와 "무엇을 판단할 것인가"(EVA)를 분리하는 것은 유효하다. 다만 각 단계의 품질이 전체 파이프라인의 병목이 된다.
마무리
가볍게 나간 공모전에 이렇게 공부가 많이 되고, 내가 진심으로 열심히 할 줄은 몰랐다. VIT모델들의 특징을 더 공부하게 되었고, 여러 방식을 시도하면서 노하우도 많이 얻으며 마무리가 됐다. 다음에도 이런 공모전이 있다면 꼭 또 한 번 도전하고 싶다.
깃허브 코드 공유: https://github.com/gonida1010/dacon-structural-stability
GitHub - gonida1010/dacon-structural-stability: AI model for predicting structural stability using multi-view images (멀티뷰
AI model for predicting structural stability using multi-view images (멀티뷰 이미지를 활용한 구조물 안정성 예측 AI 모델) - gonida1010/dacon-structural-stability
github.com
노션 개인 공부방: https://www.notion.so/32f6e129440d8023871eeca76314c94d?source=copy_link
개인 공부방(연구실) | Notion
공모전 학습 기록 메모
www.notion.so
'4. [팀] 프로젝트 및 공모전 > 4-4 구조물 안정성 물리 추론 AI 경진대회(DACON)' 카테고리의 다른 글
| [공모전] Vision 시각화 검증 상세 분석 "개인 연구용" 블로그 (0) | 2026.03.24 |
|---|---|
| [DACON 공모전] 구조물 안정성 예측 대회: EVA-Giant Dual-View 모델과 Center Crop 추론 스터디 (2) (0) | 2026.03.21 |
| [DACON 공모전] Dinov2_large 모델 분석 및 학습 진행 상황 스터디 (0) | 2026.03.12 |