
대형 언어 모델(LLM)을 활용한 복잡한 애플리케이션을 구축할 때, 랭체인과 랭그래프는 필수적인 프레임워크로 자리 잡고 있습니다. 이 글에서는 두 프레임워크의 개념과 랭그래프를 구성하는 핵심 요소들을 정리하고, 실제 코드로 어떻게 구현하는지 살펴봅니다.
1. 랭체인(LangChain)과 랭그래프(LangGraph)
1-1. 랭체인(LangChain)
대형 언어 모델(LLM)을 활용한 애플리케이션을 쉽게 개발할 수 있도록 돕는 프레임워크입니다. 프롬프트 관리, 문서 검색(Retrieval), 벡터 데이터베이스 연동, 체인(Chain) 구조를 통한 작업 연결, 외부 도구(Tool) 사용 등을 하나의 흐름으로 묶어줍니다. 이를 통해 챗봇, RAG(검색 증강 생성), 에이전트 시스템을 효율적으로 구축할 수 있습니다.
1-2. 랭그래프(LangGraph)
랭체인 생태계 안에서 에이전트나 RAG 시스템을 그래프 기반으로 설계하고 실행하게 해주는 오케스트레이션 프레임워크입니다. 기존의 RAG가 단방향의 직선형 파이프라인이었다면, 랭그래프는 분기, 반복, 조건 처리 등을 통해 "검색 → 답변 생성 → 자기평가 → 재검색"과 같은 복잡한 에이전틱 RAG(Agentic RAG) 워크플로우를 안정적으로 구현할 수 있게 해줍니다.

- 그래프 구조(Graph Structure): 데이터나 작업의 흐름을 노드(객체/작업)와 엣지(관계/연결선)로 표현하는 방식입니다. 방향성에 따라 흐름을 제어하며, 복잡한 로직을 직관적으로 탐색하고 설계할 수 있습니다.
2. 랭그래프의 4가지 필수 구성요소
랭그래프는 다음 네 가지 요소가 맞물려 유연하고 강력한 워크플로우를 완성합니다.
- 노드(Node): 워크플로우 내에서 실행되는 개별 작업 단위. (예: 질문 임베딩, DB 검색, LLM 답변 생성 등)
- 엣지(Edge): 노드와 노드를 연결하는 흐름. 한 노드의 결과가 다음 노드의 입력으로 이어지게 하는 경로입니다.
- 상태(State): 워크플로우 실행 중 그래프 전체가 공유하고 유지하는 데이터 저장소. (예: 현재까지의 대화 기록, 검색 결과 등)
- 조건 분기와 루프(Flow Control): 특정 조건에 따라 진행 경로를 바꾸거나(분기), 특정 단계를 반복(루프)하게 만드는 흐름 제어 기능입니다.
3. 상태 (State) 관리와 구현
State는 에이전트가 현재 어떤 정보를 가지고 있는지를 정의하는 데이터 구조입니다. 파이썬에서는 TypedDict나 Pydantic BaseModel을 주로 사용합니다. 단순히 데이터를 담는 것을 넘어, 상태가 업데이트될 때 어떻게 병합될지 정의하는 리듀서(Reducer) 함수와 함께 사용됩니다.
3-1. State 정의 방식 비교 (TypedDict vs Pydantic)
- TypedDict: 타입 검사기에서만 오류를 잡아주며 실행 자체는 막지 않습니다. 가볍고 단순하게 구조를 명시할 때 사용합니다.
- Pydantic BaseModel: 실제 실행 시점(Runtime)에 타입을 엄격하게 검사하여 잘못된 데이터 유입을 차단합니다.
from typing_extensions import TypedDict
from pydantic import BaseModel
# 1. TypedDict 방식 (타입 명시용)
class UserDict(TypedDict):
id: int
name: str
email: str
# 2. Pydantic 방식 (런타임 유효성 검사)
class UserBaseModel(BaseModel):
id: int
name: str
email: str
user_data = {'id': 1, 'name': '김사과', 'email': 'apple@apple.com'}
user1 = UserBaseModel(**user_data)
3-2. Reducer와 Annotated를 활용한 상태 누적
기본적으로 상태를 업데이트하면 기존 값을 덮어쓰게 됩니다. 하지만 Annotated와 리듀서 함수(예: add, add_messages)를 사용하면 데이터를 리스트에 누적하거나 대화 기록을 이어 붙일 수 있습니다.
from typing_extensions import TypedDict, Annotated
from operator import add
from langgraph.graph.message import add_messages
from langchain_core.messages import AnyMessage
# 값이 덮어씌워지지 않고 리스트에 계속 추가되도록 설계된 State
class State(TypedDict):
value1: int
# 리스트 데이터 누적
value2: Annotated[list[str], add]
# HumanMessage, AIMessage 등 대화 기록 누적
messages: Annotated[list[AnyMessage], add_messages]
4. 노드 (Node) 구현
노드는 에이전트가 수행할 실제 로직을 담은 함수입니다. State를 입력으로 받아 작업을 수행하고, 변경된 State 값을 딕셔너리 형태로 반환합니다.
간단한 챗봇 노드 구현 예시
from typing_extensions import TypedDict, Annotated
from operator import add
from langgraph.graph import StateGraph, START, END
class State(TypedDict):
messages: Annotated[list[str], add]
# 노드 역할을 할 함수 정의
def chatbot_node(state: State):
answer = "안녕하세요! 무엇을 도와드릴까요?"
print("Answer : ", answer)
# 반환하는 딕셔너리가 기존 State의 messages 리스트에 누적(add)됨
return {"messages": [answer]}
# 그래프 빌더 생성 및 노드 추가
graph_builder = StateGraph(State)
graph_builder.add_node("chatbot", chatbot_node)
# 흐름(엣지) 연결
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
# 그래프 컴파일 및 실행
graph = graph_builder.compile()
graph.invoke({"messages": ["안녕!"]})
5. 엣지 (Edge) 구현
엣지는 "다음에 어느 노드로 갈 것인가?"를 결정합니다. 조건 없이 바로 넘어가는 기본 엣지와, 상태 값에 따라 경로가 나뉘는 조건부 엣지가 있습니다.
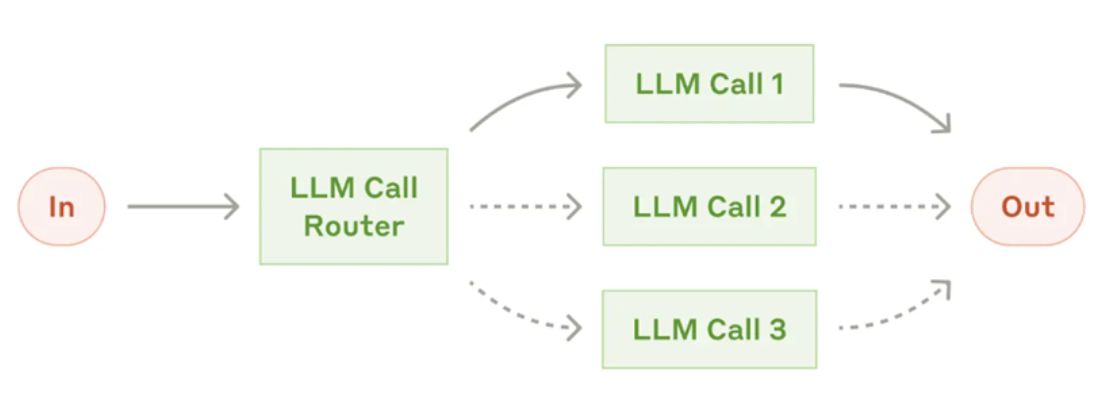
조건부 엣지 (Conditional Edge) 구현 예시
라우팅 함수를 만들어 특정 조건에 따라 흐름을 분기합니다.
class State(TypedDict):
input: str
output: str
router_builder = StateGraph(State)
# 조건 검사(라우팅) 함수
def routing_function(state: State):
if state["input"] == "isroute":
return True
return False
# 라우팅 함수의 결과(True/False)에 따라 다음 실행할 노드를 분기 처리
router_builder.add_conditional_edges(
"node_a", # 출발 노드
routing_function, # 경로를 결정할 함수
{True: "node_b", False: "node_c"} # 라우팅 결과에 따른 도착 노드 매핑
)'개념 정리 step2 > AI Agent' 카테고리의 다른 글
| [RAG 시스템 구축] 벡터 데이터베이스부터 앙상블 리트리버까지 (1) (0) | 2026.03.31 |
|---|---|
| [LangGraph] LLM 도구 사용법 (Tool Calling & Agents) (5) (0) | 2026.03.23 |
| [AI Agent] "Tool Calling Agent의 개념"과 "Tavily"를 활용한 웹 검색 챗봇 구현 (4) (0) | 2026.03.20 |
| [LangGraph] 상태 업데이트 및 워크플로우 제어 (3) (0) | 2026.03.19 |
| [Agent 개념] AI 에이전트(Agent)부터 에이전틱 RAG 워크플로우까지 (1) (0) | 2026.03.16 |