
안녕하세요! 강화학습을 공부하다 보면 가장 먼저 마주치는 개념이 바로 MDP(Markov Decision Process)입니다. 이번 글에서는 MDP가 무엇인지, 그리고 그 근간이 되는 MP와 MRP부터 알아보겠습니다.
1. Markov Decision Process (MDP)란?
Markov Decision Process(MDP, 마르코프 결정 과정)는 의사결정을 포함한 확률적 모델입니다. 어떤 상태(State)에서 에이전트가 행동(Action)을 선택하면, 그에 따라 확률적으로 다음 상태로 전이되고 보상(Reward)을 받는 구조를 말합니다.
MDP는 기본적으로 다음 5가지 요소로 구성됩니다.
- 상태 (State, S)
- 행동 (Action, A)
- 전이 확률 (Transition Probability, P)
- 보상 (Reward, R)
- 할인율 (Discount Factor, γ) - 감마값
강화학습의 목표는 이 MDP 환경 속에서 에이전트가 장기적인 누적 보상(기대 수익)을 최대화하는 최적 정책(Policy)을 학습하는 것입니다.
1-1 마르코프 성질 (Markov Property)
미래 상태가 과거 전체의 이력에 의존하지 않고 오직 '현재 상태'에만 의존한다는 성질입니다. 현재 상태가 과거의 유의미한 정보를 모두 요약하고 있다고 가정하여, 상태 전이와 의사결정을 수학적으로 단순화합니다.

1-2 마르코프 한 상태 (Markov State)
예시: 바둑
바둑판 위의 현재 돌 배치 전체가 하나의 상태입니다. 다음 수 이후의 판세는 과거에 어떤 순서로 바둑돌을 두었는지와는 무관하고, 오직 현재 바둑판의 배치와 이번에 선택한 착수 위치에 의해서만 결정됩니다. 이처럼 "현재의 모습"이 과거의 정보를 모두 담고 있다면 마르코프 상태라고 부릅니다.
1-3 마르코프 하지 않은 상태 (Non-Markov State)
예시: 다이어트
"지금 배가 고프다"는 현재 상태만으로는 다음 행동(폭식을 할지, 참을지)을 예측하기 어렵습니다. 어제 굶었는지, 스트레스를 많이 받았는지 등 과거의 이력이 행동에 큰 영향을 주기 때문입니다.
💡 마르코프하게 만들려면?
현재 상태만으로 부족하다면 상태의 정의를 확장하면 됩니다.
- 상태 확장: 여러 과거의 관측 프레임을 모아 하나의 큰 상태로 만듭니다. (예: 아타리 게임에서 최근 4프레임을 묶어서 상태로 사용)
- 메모리 사용: RNN(순환 신경망) 등을 사용해 과거의 정보를 은닉 상태(Hidden State)로 기억하게 만듭니다. (이를 POMDP, 부분 관측 마르코프 결정 과정 환경을 풀 때 주로 사용합니다.)
2. Markov Process (MP)
Markov Process는 “현재 상태만 알면 미래 상태를 예측할 수 있다”는 마르코프 성질을 따르는 확률적 상태 전이 과정입니다. 에이전트의 행동이나 보상없이 오직 상태의 변화만 관찰하는 모델입니다.
2-1 상태 전이 다이어그램 (그래프 표현)
- 노드(Node): 상태(State)
- 화살표: 상태 전이(Transition)
- 화살표 위 숫자: 전이 확률
- 예: S1 → S2 (0.7)은 S1에서 70% 확률로 S2로 이동한다는 뜻입니다.

2-2. 전이 확률 행렬 (Transition Matrix)
이러한 상태 전이를 수학적인 행렬로 표현할 수 있습니다.
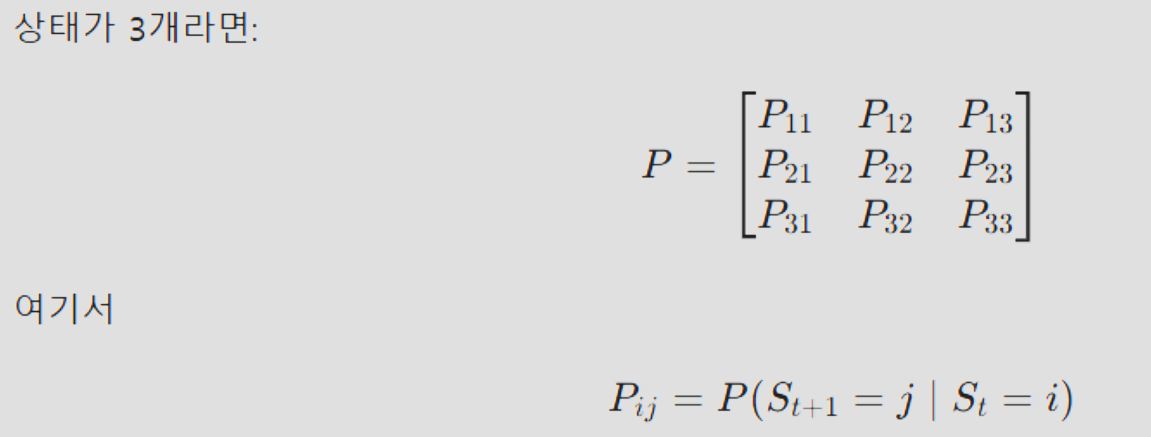

주의점:
현재 상태에서 다음 상태로 무조건 이동(또는 제자리 유지)해야 하므로, 각 행(Row)의 확률 합은 반드시 1이 되어야 합니다.
3. Markov Reward Process (MRP)
Markov Reward Process(MRP)는 앞서 배운 MP에 Reward과 γ, Gamma이 추가된 모델입니다. 아직 에이전트의 '행동'은 없으며, 시간이 흐름에 따라 상태가 변하고 그에 따른 보상을 받습니다.

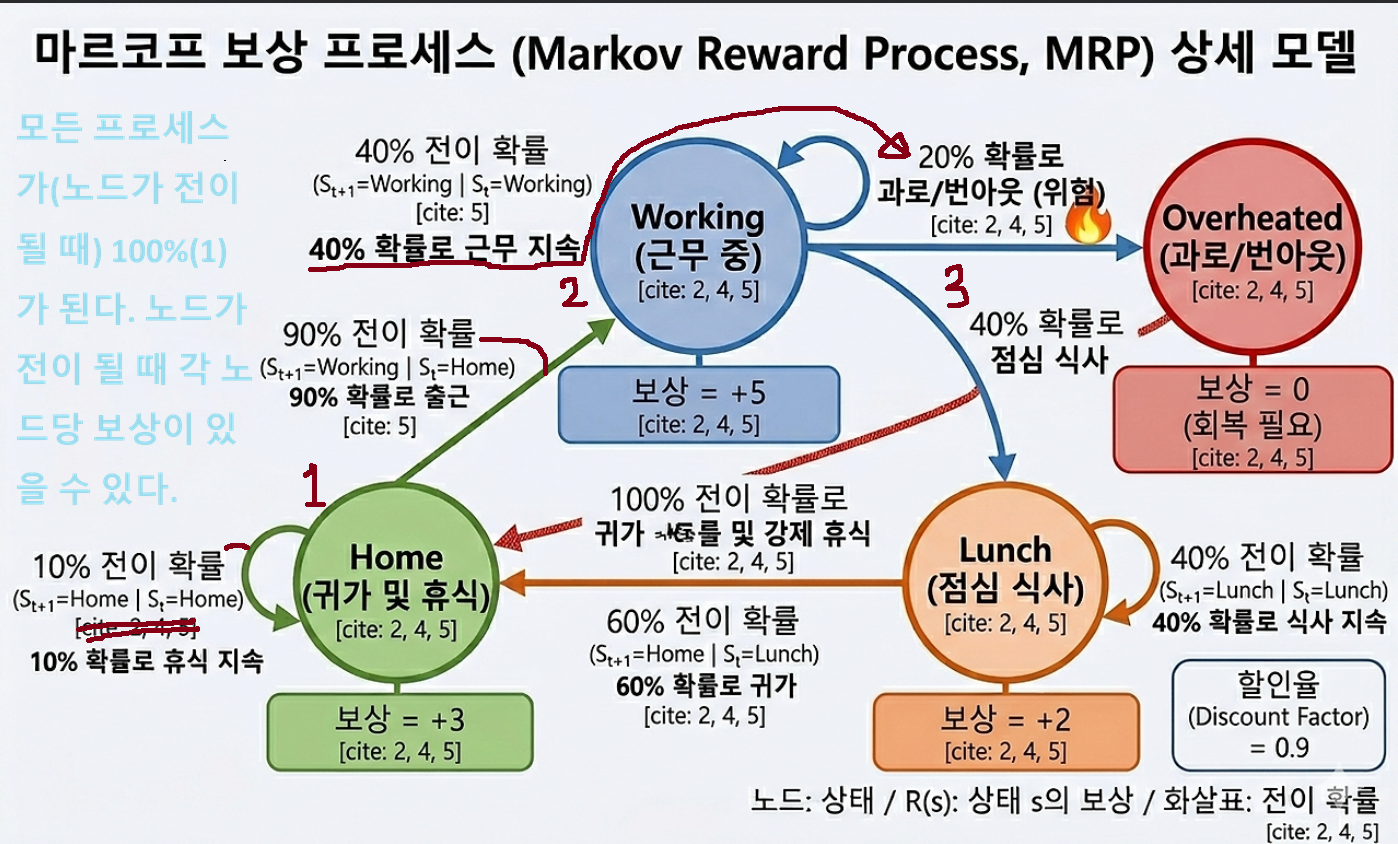
3-1 감마(γ, 할인율)
감마는 미래에 받을 보상을 현재 가치로 얼마나 반영할지를 결정하는 계수(0 ~ 1 사이의 값)입니다.
- γ가 0에 가까울수록: "지금 당장이 중요해!" 즉각적인 보상만 고려하며 매우 단기적인 시각을 가집니다.
- γ가 1에 가까울수록: "미래를 대비하자!" 먼 미래의 보상도 현재 보상과 비슷하게 반영하여 장기적인 시각을 가집니다.
3-2 가치 함수 (Value Function)
특정 상태에서 시작했을 때, 앞으로 받을 보상들의 총합(기대 수익)을 수치화한 것입니다. MRP와 MDP를 지탱하는 핵심 개념인 벨만 방정식(Bellman Equation)으로 표현할 수 있습니다.
(해석: 현재 상태의 가치는 '다음 상태로 가면서 받을 즉시 보상'과 '할인된 다음 상태의 가치'의 합의 기댓값과 같다.)
단순히 현재 보상이 크다고 좋은 것이 아니라, 그 다음 상태가 지옥(-10점)으로 갈 확률이 높다면 해당 상태의 전체 가치는 낮아지게 됩니다.
4. Markov Decision Process (MDP)
4-1 MP/MRP와의 차이점
MP와 MRP는 주체적인 의사결정 없이 시스템이 확률적으로 흘러가는 과정입니다. 하지만 MDP에는 에이전트의 '행동(Action)'이 추가됩니다. 에이전트가 어떤 선택을 하느냐에 따라 미래의 통제권이 주어지며, 장기 보상을 최적화할 수 있습니다.
4-2 행동 (Action)
행동은 에이전트가 환경에 영향을 주기 위해 내리는 결정입니다. 이산적(상/하/좌/우)일 수도 있고 연속적(운전대 각도, 로봇 관절의 힘)일 수도 있습니다. 어떤 행동을 하느냐에 따라 전이되는 상태와 받는 보상이 달라집니다.
4-3 정책 (Policy, $\pi$)
"이 상태에서는 어떤 행동을 해야 하는가?"에 대한 에이전트의 행동 매뉴얼입니다.
- 결정적 정책 (Deterministic): 상태 $S$에서 무조건 행동 $A$를 한다. (예: 배고프면 무조건 밥을 먹는다)
- 확률적 정책 (Stochastic): 상태 $S$에서 행동 $A_1$을 할 확률 70%, $A_2$를 할 확률 30%. (예: 배고프면 70% 확률로 밥, 30% 확률로 빵을 먹는다)
4-4 가치 (Value)
가치는 단기 보상이 아닌 미래까지 포함한 장기적 관점에서의 '좋음의 정도'입니다. 상태 가치 함수 $V(s)$와 행동 가치 함수 $Q(s, a)$가 있으며, 강화학습은 이 가치를 최대한 높이는 최적 정책을 찾는 과정입니다.
5. MDP 실습 예제 및 문제 풀이
퇴근 후 직장인의 상태 변화를 파이썬 코드로 시뮬레이션해 봅니다.
state = 'working'
total_return = 0
gamma = 0.9
stack = 0
while True:
print(f'[Step {stack}] 현재 상태: {state}')
if state == 'working':
print('선택지: Gym / Home / Working')
action = input('행동 선택: ').strip().lower()
if action == 'gym':
next_state, reward = 'gym', 5
elif action == 'home':
next_state, reward = 'home', 2
elif action == 'working':
next_state, reward = 'working', 3
else:
continue
elif state == 'gym':
print('선택지: Home / Working')
action = input('행동 선택: ').strip().lower()
if action == 'home':
next_state, reward = 'home', 2
elif action == 'working':
next_state, reward = 'working', 4
else:
continue
elif state == 'home':
print('집에 도착했습니다. (종료)')
reward = 10
discounted_reward = (gamma ** stack) * reward
total_return += discounted_reward
print(f'최종 Return (누적 가치): {total_return:.4f}')
break
discounted_reward = (gamma ** stack) * reward
total_return += discounted_reward
print(f'이번 보상: {reward}, 감가 적용 보상: {discounted_reward:.4f}')
print(f'현재까지 누적 Return: {total_return:.4f}\n')
state = next_state
stack += 1
문제 1. Return 계산하기
Q. working > gym > working > home 순서로 행동했을 때 누적 Return 값은? ($\gamma = 0.9$)
풀이 과정:
- working에서 gym 선택: $5 \times (0.9^0) = 5$
- gym에서 working 선택: $4 \times (0.9^1) = 3.6$
- working에서 home 선택: $2 \times (0.9^2) = 1.62$
- home 도달 보상: $10 \times (0.9^3) = 7.29$
정답: $5 + 3.6 + 1.62 + 7.29 =$ 17.51
문제 2. Policy 평가 비교
Q. 다음 두 정책 중 Return이 더 큰 것을 고르시오. ($\gamma = 0.9$)
- 정책 A: working > working > working > home
- 정책 B: working > gym > working > home
풀이 과정:
- 정책 A 계산:$= 3 + 2.7 + 1.62 + 7.29 =$ 14.61
- $3(0.9^0) + 3(0.9^1) + 2(0.9^2) + 10(0.9^3)$
- 정책 B 계산 (문제 1 결과): 17.51
정답: 정책 B가 누적 보상이 더 크므로 더 좋은 정책입니다.
문제 3. $\gamma$에 따른 에이전트의 성향 변화
Q. $\gamma$ 값이 각각 0.1, 0.9, 1.0일 때 에이전트의 행동 전략은 어떻게 달라질까?
정답 및 해설:
- $\gamma = 0.1$ (근시안적 에이전트): 감가율이 매우 커서 한 스텝만 지나도 보상의 가치가 1/10로 줄어듭니다. 에이전트는 장기적인 계획을 세우지 않고, 당장 눈앞에서 가장 높은 보상을 주는 행동만 반복적으로 선택합니다.
- $\gamma = 0.9$ (균형 잡힌 에이전트): 당장의 보상도 챙기면서 미래의 큰 보상을 위해 기꺼이 현재의 작은 손해를 감수할 줄 압니다. 가장 흔하게 쓰이는 설정값입니다.
- $\gamma = 1.0$ (할인 없음): 미래 보상을 전혀 깎지 않습니다. 만약 종료 상태 없는 무한루프 환경이라면, 누적 보상이 무한대로 발산할 수 있어 수학적으로 가치 함수 계산이 불가능해질 위험이 있습니다.
6. 마무리
https://youtube.com/shorts/GBikn2RwU_A?si=n7NP8b5Cu0x0HdHz
강화학습이라는 개념이 세상에 등장한 지는 제법 오랜 시간이 흘렀습니다. 하지만 에이전트가 환경과 상호작용하며 시행착오를 통해 스스로 최적의 길을 찾아가는 과정은, 공부를 하면 할수록 논리적이고 깊은 흥미를 자극합니다.
특히 오늘 다룬 MDP(마르코프 결정 과정)는 단순히 낡은 이론에 머물지 않습니다. 세상을 놀라게 했던 알파고(AlphaGo)부터, 우리가 매일 사용하는 챗GPT의 핵심 기술인 RLHF(인간 피드백 기반 강화학습), 그리고 자율주행과 로봇 공학에 이르기까지 최신 인공지능 트렌드를 관통하는 가장 튼튼한 수학적 기반이 바로 이 MDP입니다.
처음에는 상태, 행동, 보상, 할인율 같은 용어들이 다소 추상적으로 느껴질 수 있지만, 퇴근 후 헬스장을 갈지 집으로 곧장 갈지 고민하는 우리의 일상처럼 친숙한 예시로 접근하면 훨씬 직관적으로 와닿습니다.
이번 글에서 강화학습이 돌아가는 환경과 규칙(MDP)을 완벽하게 세팅했으니, 다음 포스팅에서는 이 환경 속에서 에이전트가 어떻게 가치를 수학적으로 계산해 내는지, 그 유명한 벨만 방정식(Bellman Equation)과 본격적인 강화학습 알고리즘들에 대해 이어서 정리해 보겠습니다.
'개념 정리 step2 > 강화 학습' 카테고리의 다른 글
| [강화학습] Deep Reinforcement Learning 개념 (0) | 2026.03.03 |
|---|---|
| [강화학습] TD Learning (시간차 학습) 개념, 랜덤 벽 GridWorld 실습 (0) | 2026.03.01 |
| [강화학습] Monte Carlo Learning 정리 (0) | 2026.02.28 |
| [강화학습] 벨만 기대 방정식 (Bellman Expectation Equation) (0) | 2026.02.27 |
| [강화학습] 강화학습 기본 개념 정리 (0) | 2026.02.21 |