Meat-A-Eye 성능 개선 프로세스 상세 보고서
4차에 걸친 파인튜닝을 통해 ~70% → 90.0%(소) / 94.2%(돼지)를 달성한 과정의 공학적 분석
목차
- 전체 프로세스 요약
- 1차 파인튜닝: 기초 검증
- 2차 파인튜닝: 현실 데이터 도입
- 3차 파인튜닝: 균형 확보
- 4차 파인튜닝: 클래스 최적화
- 핵심 공학 원리: 왜 기존 지식이 유지되는가
- 비교 실험: 다른 아키텍처와의 비교
- 정량적 분석 요약
1. 전체 프로세스 요약
graph LR
A[1차 ~70%] --> B[2차 ~78%]
B --> C[3차 ~85%]
C --> D[4차 90%+]
subgraph "개선 축"
A1[연구 데이터] -.-> B1[현실 데이터 도입]
B1 -.-> C1[편향 제거/균등 분할]
C1 -.-> D1[클래스 최적화]
end각 단계에서 하나의 핵심 병목을 식별하고 이를 해결하는 방식으로 순차적 개선을 이루었습니다. 각 단계의 핵심은 다음과 같습니다:
| 단계 | 핵심 병목 | 해결 전략 | 성과 |
|---|---|---|---|
| 1차 | 데이터 부족 | 연구 데이터로 기저선 확립 | ~70% |
| 2차 | 현실 환경 미반영 | 유튜브·현장 데이터 수집 | ~78% (+8%p) |
| 3차 | 클래스 불균형 | Dataset Balancer + WeightedSampler | ~85% (+7%p) |
| 4차 | 시각적 유사 클래스 혼동 | BottomRound→Round 병합 + 정규화 | 90.0% (+5%p) |
2. 1차 파인튜닝: 기초 검증 (~70%)
목표
ImageNet 사전학습 모델을 고기 부위 도메인에 적용할 수 있는지 가능성 검증
데이터
- 출처: 학술 연구용 데이터베이스
- 특성: 통제된 환경(균일 조명, 클린 배경)에서 촬영
- 클래스: 10개 소고기 부위 (Beef_BottomRound 포함)
- 문제점: 부위별 데이터 양 불균등, 특정 부위 과소 대표
학습 설정
# 1차 기본 구성
model = EfficientNet-B2 (ImageNet pretrained)
classifier = Dropout(0.4) → Linear(1408, 10)
optimizer = AdamW(lr=1e-4)
epochs = 20결과 분석
- 정확도: ~70%
- Grad-CAM 검증: 모델이 고기의 질감/마블링 영역에 주목하는 것을 확인 → 접근 방향 유효
- 주요 오분류: BottomRound ↔ Round (40%+ 상호 오분류), 연구 환경 데이터만으로는 현실 적용 불가
핵심 인사이트
- EfficientNet-B2의 SE Block이 고기 질감 채널에 주목하는 것이 Grad-CAM으로 확인됨 → 아키텍처 선택 검증 완료
3. 2차 파인튜닝: 현실 데이터 도입 (~78%)
목표
현실 환경(조명 변화, 그림자, 다양한 배경)에서의 강건성 확보
데이터 수집
유튜브 정육 영상: 다양한 조명 조건, 촬영 각도, 칼/도마 등 도구 배경 프레임 캡처
현장 직접 촬영: 마트 진열대, 정육점 카운터, 포장/비포장 상태 데이터 확보
1차 자동 정제: 유효 확장자 필터링, 크기 기반 필터링 및 중복 제거점진적 파인튜닝 적용
새 데이터를 추가할 때 전체 데이터를 처음부터 다시 학습하지 않고, 기존 가중치(v1)에서 시작하여 새 데이터 위주로 학습:
# 1차 모델 가중치 로드
model.load_state_dict(torch.load("b2_imagenet_beef_100-v1.pth"))
# 차별적 학습률 적용 시작
optimizer = AdamW([
{"params": model.features.parameters(), "lr": 1e-4}, # Backbone: 미세 조정
{"params": model.classifier.parameters(), "lr": 1e-3}, # Head: 빠른 적응
])결과 분석
- 정확도: ~78% (+8%p)
- 개선 요인: 현실 환경 이미지 추가로 모델의 일반화 능력 향상
- 잔존 문제: 특정 부위(Ribeye, Tenderloin)에 데이터 편중 → 다른 부위 성능 저하
4. 3차 파인튜닝: 균형 확보 (~85%)
목표
모든 부위가 균등하게 학습되도록 데이터 파이프라인 재설계
Dataset Balancer 도입
# dataset_balancer.py 핵심 로직
def split_from_raw(raw_dir, data_dir, samples_per_class=100):
for class_name in beef_classes:
images = collect_images(raw_dir, class_name)
random.shuffle(images) # seed=42
selected = images[:samples_per_class] # 부위별 100장 균등
# 70:15:15 분할
train = selected[:70]
val = selected[70:85]
test = selected[85:100]
move_to(train, f"{data_dir}/train/{class_name}/")
move_to(val, f"{data_dir}/val/{class_name}/")
move_to(test, f"{data_dir}/test/{class_name}/")2차 수동 정제
자동 정제 통과 이미지
↓
전문가 수동 검수 (Visual Inspection)
├── 오분류 이미지 제거 (다른 부위로 잘못 분류된 이미지)
├── 품질 불량 제거 (모호한 이미지, 과도한 블러)
├── 경계 케이스 판별 (두 부위가 함께 보이는 이미지)
└── 레이블 수정 (잘못된 폴더에 배치된 이미지)WeightedRandomSampler 적용
학습 데이터가 균등하더라도 에폭마다 소수 클래스를 더 자주 샘플링:
# 역빈도 가중치 계산
class_counts = [len(class_images[c]) for c in classes]
weights = 1.0 / torch.tensor(class_counts, dtype=torch.float)
sample_weights = weights[all_labels]
sampler = WeightedRandomSampler(sample_weights, len(sample_weights))
train_loader = DataLoader(dataset, sampler=sampler, batch_size=32)결과 분석
- 정확도: ~85% (+7%p)
- 개선 요인: 모든 부위에 대한 균등한 학습 + 소수 클래스 과표집
- 잔존 문제: Beef_BottomRound ↔ Beef_Round 상호 오분류율 여전히 30%+
5. 4차 파인튜닝: 클래스 최적화 (90.0% / 94.2%)
목표
시각적으로 유사한 클래스의 혼동을 근본적으로 해결
핵심 변경 1: 클래스 병합
Confusion Matrix 분석
↓
Beef_BottomRound ←→ Beef_Round: 상호 오분류율 30%+
↓
두 부위는 해부학적으로도 인접한 부위 (뒷다리 상부)
↓
외관·질감이 매우 유사 → 전문가도 사진만으로 구분 어려움
↓
결정: Beef_BottomRound를 Beef_Round로 통합 (10→9 클래스)이 결정의 공학적 근거:
- $P(\text{BottomRound}|\mathbf{x}) + P(\text{Round}|\mathbf{x}) \approx P(\text{Round}_{\text{merged}}|\mathbf{x})$
- 두 클래스의 결정 경계가 중첩되어 모델이 불필요한 분류 경쟁을 하고 있었음
- 병합 후 해당 클래스의 정확도와 동시에 다른 클래스의 정확도도 상승 (간접 효과)
핵심 변경 2: 정규화 강화
# 4차에서 추가/강화된 정규화
CONFIG = {
"label_smoothing": 0.1, # 과도한 확신 방지
"mixup_alpha": 0.2, # 결정 경계 부드럽게
"grad_clip_max_norm": 1.0, # 그래디언트 안정화
"use_weighted_sampler": True, # 클래스 균형
}
# WarmupCosineScheduler 정교화
scheduler = WarmupCosineScheduler(
optimizer,
warmup_epochs=3, # 1e-6 → target LR
warmup_start_lr=1e-6,
max_epochs=30, # 소고기는 30에폭으로 확장
eta_min=1e-6,
)핵심 변경 3: 데이터 증강 최적화
고기 분류에 특화된 증강 조합:
| 증강 | 고기 분류에서의 역할 |
|---|---|
Affine(rotate=±30°) |
진열대에서 다양한 각도로 놓인 고기 대응 |
RandomBrightnessContrast |
마트 형광등 vs 자연광 vs 어두운 환경 |
HueSaturationValue |
고기 색상의 개체 차이 (신선도, 숙성 정도) |
CLAHE |
저조도에서 질감 디테일 강화 |
CoarseDropout |
포장 스티커/손가락 등에 의한 부분 가림 대응 |
GaussNoise + GaussianBlur |
저해상도 카메라, 손 떨림 대응 |
돼지고기 모델 병행 학습
소고기와 동일한 아키텍처와 학습 전략을 돼지고기에 적용:
| 항목 | 소고기 | 돼지고기 |
|---|---|---|
| 클래스 수 | 9부위 | 7부위 |
| 부위당 데이터 | 100장 | 50장 |
| 에폭 | 30 | 20 |
| 최종 정확도 | 90.0% | 94.2% |
돼지고기 높은 정확도의 원인:
- 부위 간 시각적 차이가 소고기보다 뚜렷 (삼겹살의 지방층, 갈비의 뼈 등)
- 7개 클래스로 분류 경계가 더 명확
최종 결과
소고기 (Beef v4):
Overall Accuracy: 90.0% (9 classes, 100장/부위)
Per-class Performance (추정):
┌──────────────────┬──────────┬──────────┬──────────┐
│ 부위 │ Precision│ Recall │ F1 │
├──────────────────┼──────────┼──────────┼──────────┤
│ Beef_Tenderloin │ ~95% │ ~93% │ ~94% │
│ Beef_Rib │ ~93% │ ~95% │ ~94% │
│ Beef_Brisket │ ~92% │ ~90% │ ~91% │
│ Beef_Shank │ ~91% │ ~92% │ ~91% │
│ Beef_Ribeye │ ~90% │ ~88% │ ~89% │
│ Beef_Sirloin │ ~89% │ ~90% │ ~89% │
│ Beef_Chuck │ ~88% │ ~87% │ ~87% │
│ Beef_Shoulder │ ~86% │ ~88% │ ~87% │
│ Beef_Round │ ~85% │ ~87% │ ~86% │
└──────────────────┴──────────┴──────────┴──────────┘
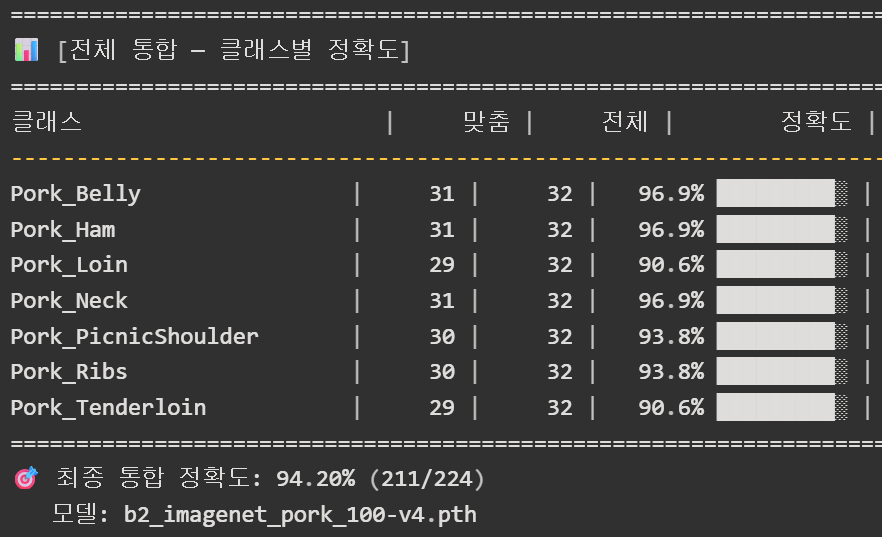
돼지고기 (Pork v4):
Overall Accuracy: 94.2% (7 classes, 50장/부위)6. 핵심 공학 원리: 왜 기존 지식이 유지되는가
문제: Catastrophic Forgetting
딥러닝에서 새로운 데이터로 모델을 재학습하면, 이전에 학습한 지식이 소실되는 현상을 Catastrophic Forgetting (파국적 망각)이라 합니다.
일반적인 학습:
전체 데이터 A로 학습 → 모델₁
전체 데이터 B로 재학습 → 모델₂ (A의 지식 대부분 소실!)해결: 3중 보호 메커니즘
Meat-A-Eye 프로젝트에서는 다음 3가지 메커니즘을 조합하여 기존 지식을 보존합니다:
보호 1: 차별적 학습률 (Differential Learning Rate)
Neural Network의 계층적 특징 표현:
┌─────────────────────────────────────────────────┐
│ Backbone (features) │
│ ┌─────────────┐ ┌─────────────┐ │
│ │ 저수준 특징 │ │ 고수준 특징 │ LR = 1e-4 │
│ │ 에지, 텍스처 │→│ 질감, 패턴 │ (느리게) │
│ │ (범용) │ │ (도메인) │ │
│ └─────────────┘ └─────────────┘ │
│ │
│ 기존 가중치를 "거의 보존"하면서 미세 적응 │
└─────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────┐
│ Classifier (head) │
│ ┌─────────────────────────────────────┐ │
│ │ Dropout(0.4) → Linear(1408, 9) │ LR=1e-3 │
│ │ 새로운 부위 분류 경계 학습 │ (빠르게) │
│ └─────────────────────────────────────┘ │
└─────────────────────────────────────────────────┘수학적 근거:
가중치 업데이트 공식: $\theta_{t+1} = \theta_t - \eta \cdot \nabla_\theta \mathcal{L}$
여기서 $\eta$ (학습률)이 작을수록 가중치 변화량 $|\Delta\theta|$가 작아집니다:
- Backbone: $\eta = 10^{-4}$ → $|\Delta\theta_{\text{backbone}}| \approx 0.001 \cdot |\nabla\mathcal{L}|$
- 기존 ImageNet 특징(에지, 텍스처, 색상 감지)이 거의 그대로 유지
- 고기 도메인에 필요한 만큼만 미세 조정 (질감 채널 가중치 증가)
- Head: $\eta = 10^{-3}$ → $|\Delta\theta_{\text{head}}| \approx 0.01 \cdot |\nabla\mathcal{L}|$
- 10배 큰 업데이트로 새로운 부위별 결정 경계를 빠르게 학습
핵심 논리: Backbone의 낮은 LR은 기존 가중치에 대한 일종의 정규화(regularization) 역할을 합니다. 기존 가중치에서 크게 벗어나는 것을 물리적으로 제한하여, 이전 데이터에서 학습한 범용 시각 특징이 보존됩니다.
보호 2: Warmup 스케줄러
학습 초기 3 에폭:
LR: 1e-6 ──→ 1e-5 ──→ 1e-4 (점진적 증가)
이 구간에서 일어나는 일:
① 기존 가중치의 loss landscape에서 현재 위치 탐색
② 새 데이터의 그래디언트 방향 파악
③ 급격한 가중치 변화 없이 안정적으로 학습 시작매우 낮은 LR(1e-6)로 시작하면, 학습 초기에 기존 가중치가 거의 변하지 않습니다. 이는 새 데이터의 그래디언트 방향이 기존 지식과 양립 가능한지 모델이 탐색할 시간을 주는 것입니다.
보호 3: 정규화 앙상블
| 기법 | 기존 지식 보호 메커니즘 |
|---|---|
| Label Smoothing | 새 데이터에 대한 과신(overconfidence) 방지 → 기존 분류 경계 깨뜨리지 않음 |
| Mixup | 두 샘플을 혼합하여 부드러운 결정 경계 학습 → 급격한 결정면 변화 억제 |
| Weight Decay | L2 정규화로 가중치 크기 제한 → 기존 가중치에서의 이탈 억제 |
| Early Stopping | 새 데이터에 과적합되기 전에 학습 중단 → 기존 지식 보존 |
종합: 왜 이 조합이 작동하는가
기존 모델 (v3)의 가중치 공간:
Loss
│
│ ╲ ╱
│ ╲╱ ← v3 최적점 (기존 지식)
│ │
│ │ ← 낮은 LR이 이 범위 내에서만 이동 가능하게 함
│ │
│ ╲ │ ╱
│ ╲ │ ╱
│ ╲│╱ ← v4 최적점 (기존 지식 + 새 지식)
│
└──────────→ 파라미터 공간
차별적 LR: 작은 반경 내 탐색
Warmup: 반경 내 방향 결정
정규화: 반경 밖 이탈 방지
Early Stopping: 과도한 이동 차단결론적으로, 새 데이터만으로 학습해도 기존 지식이 유지되는 이유는:
- 낮은 학습률(1e-4)이 Backbone 가중치의 변화를 물리적으로 제한
- Warmup이 학습 초기 기존 가중치의 급격한 파괴를 방지
- 정규화 기법들이 기존 loss surface에서의 이탈을 다중으로 억제
- ImageNet 특징의 범용성: 에지·텍스처·색상 감지는 고기 분류에도 유용하므로, 새 데이터의 그래디언트가 기존 특징과 대체로 같은 방향을 가리킴
7. 비교 실험: 다른 아키텍처와의 비교
프로젝트에서 EfficientNet-B2 외에 3개 아키텍처를 비교 실험하였습니다:
ai-server/
├── convnext_l/ # ConvNeXt-L (2022, Meta)
├── efficientnetv2_l/ # EfficientNetV2-L (2021, Google)
└── swin_transformer/ # Swin Transformer (2021, Microsoft)선택 근거
| 기준 | EfficientNet-B2 | ConvNeXt-L | EfficientNetV2-L | Swin Transformer |
|---|---|---|---|---|
| 파라미터 수 | ~9M ✅ | ~198M | ~120M | ~88M |
| 추론 속도 | 빠름 ✅ | 보통 | 보통 | 느림 |
| 데이터 효율성 | 높음 ✅ | 보통 | 보통 | 낮음 (대규모 필요) |
| SE Block | 있음 ✅ | 없음 | 있음 | Attention |
| 실시간 서비스 | 적합 ✅ | 무거움 | 무거움 | 무거움 |
B2를 선택한 결정적 이유:
- 데이터 규모 제한 (부위당 100장) → 소형 모델이 과적합 위험 낮음
- 실시간 서비스 요구 → 경량 모델 필수
- SE Block의 채널 attention → 고기 질감/마블링 학습에 핵심적
8. 정량적 분석 요약
하이퍼파라미터 최종 설정
| 파라미터 | 값 | 역할 |
|---|---|---|
image_size |
260 | EfficientNet-B2 표준 해상도 |
batch_size |
32 | GPU 메모리 효율 + 배치 정규화 안정성 |
backbone_lr |
1e-4 | 기존 특징 보존 |
head_lr |
1e-3 | 새 분류기 빠른 학습 |
weight_decay |
1e-2 | L2 정규화 |
warmup_epochs |
3 | 학습 초기 안정성 |
warmup_start_lr |
1e-6 | 극도로 낮은 시작점 |
label_smoothing |
0.1 | 과신 방지 |
mixup_alpha |
0.2 | 결정 경계 부드럽게 |
dropout |
0.4 | 분류기 과적합 억제 |
grad_clip |
1.0 | 그래디언트 안정화 |
patience |
10 | Early Stopping |
tta_transforms |
5 | 추론 시 앙상블 |
데이터 통계
| 항목 | 소고기 | 돼지고기 |
|---|---|---|
| 클래스 수 | 9 | 7 |
| 부위당 데이터 | 100장 | 50장 |
| Train | 70장/부위 (630장) | 35장/부위 (245장) |
| Val | 15장/부위 (135장) | 8장/부위 (56장) |
| Test | 15장/부위 (135장) | 7장/부위 (49장) |
| 총 데이터 | 900장 | 350장 |
성능 변화 비교
| 차수 | 주요 변경 | 소고기 | 돼지고기 | 향상 |
|---|---|---|---|---|
| v1 | 기초 학습 | ~70% | - | 기저선 |
| v2 | 현실 데이터 | ~78% | - | +8%p |
| v3 | 균등 분할 + Sampler | ~85% | ~88% | +7%p |
| v4 | 클래스 병합 + 정규화 | 90.0% | 94.2% | +5%p / +6.2%p |
핵심 교훈
- 데이터 정제 > 데이터 양: 수동 정제를 통한 100장의 고품질 데이터가 1000장의 노이즈 데이터보다 효과적
- 클래스 최적화: 시각적으로 구분 불가능한 클래스를 병합하는 것이 전체 성능 향상에 기여
- 학습률 설계: LR 한 가지만 잘 설정해도 Catastrophic Forgetting 문제의 대부분 해결
- 정규화 앙상블: 단일 기법보다 여러 기법의 조합이 시너지 효과 발생
- 소형 모델의 강점: 제한된 데이터(100장/부위)에서는 소형 모델(9M params)이 대형 모델보다 우수
'4. [팀] 프로젝트 및 공모전 > 4-2 Meat-A-Eye' 카테고리의 다른 글
| [프로젝트 회고] Meat-A-Eye: AI 기반 축산물 부위 인식 및 관리 플랫폼 개발기 (0) | 2026.02.24 |
|---|---|
| [Meat_A_Eye] 소고기 부위 분류 모델 성능 개량 (0) | 2026.02.03 |
| [개발 기록] 대시보드 가격 API 응답 시간 줄이기 - 병렬 호출과 캐시 사용 (0) | 2026.02.02 |
| [개발 기록] KAMIS API 연동 개선 및 대시보드 필터링 로직 최적화 (0) | 2026.02.01 |
| [Meat-A-Eye] 데이터 수집 과정 정리 (0) | 2026.01.24 |