안녕하세요!
오늘은 비지도 학습의 대표 주자이자, 생성 모델의 뿌리가 되는 오토인코더(Autoencoder)에 대해 깊게 파헤쳐 보겠습니다. 단순히 개념만 잡는 것이 아니라, TensorFlow와 PyTorch를 이용한 실전 구현까지 상세히 정리했습니다.
생성 모델이라는 점을 다시 한 번 생각하면서 공부 정리를 시작해 보도록 하겠습니다.
오토인코더(Autoencoder)
오토인코더는 입력 데이터를 효율적으로 압축(Encoding)하고, 이를 다시 원래대로 복원(Decoding)하는 과정을 통해 데이터의 핵심 특징을 학습하는 신경망입니다.
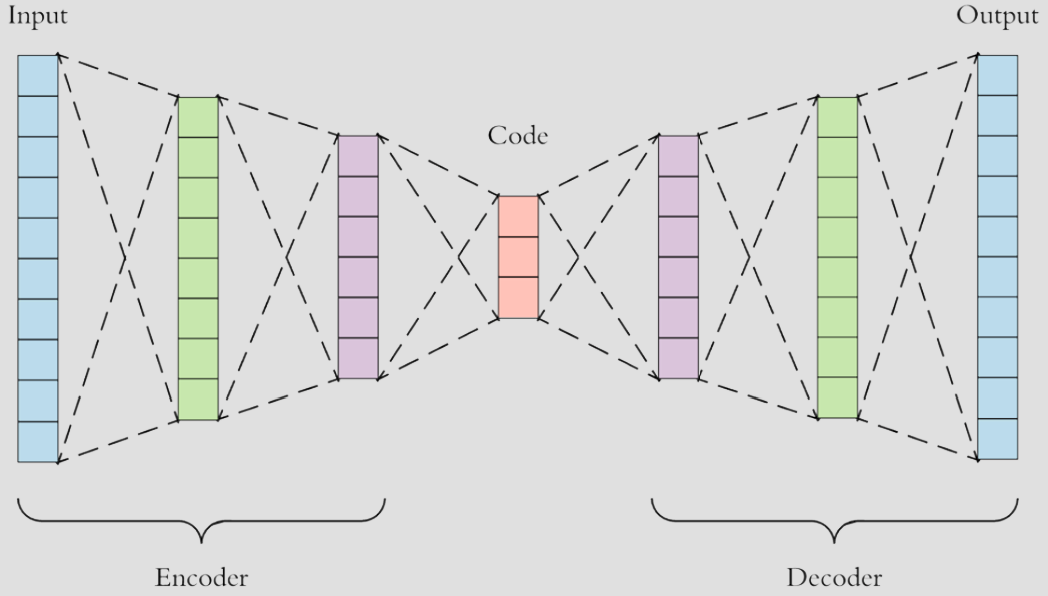
핵심 구조
- 인코더 (Encoder):
- 고차원 입력 데이터를 저차원의 잠재 표현(Latent Space)으로 변환합니다. 일종의 '데이터 압축기' 역할을 하며, 사소한 노이즈는 버리고 가장 중요한 정보만 남깁니다.
- 디코더 (Decoder):
- 압축된 잠재 벡터를 다시 입력 데이터와 같은 형태로 복원합니다. '데이터 재생기'라고 볼 수 있습니다.
- 재구성 오류 (Reconstruction Error):
- 원본과 복원 결과 사이의 차이를 의미하며, 모델은 이 오차를 최소화하는 방향으로 학습합니다.
1. 기본 오토인코더 구현 (TensorFlow/Keras)
MNIST 숫자 데이터를 사용하여 입력 이미지를 자기 자신으로 복원하는 기본적인 CNN 기반 오토인코더입니다.
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, UpSampling2D
import matplotlib.pyplot as plt
import numpy as np
# 데이터 로드 및 전처리
(X_train, _), (X_test, _) = mnist.load_data()
X_train = X_train.reshape(-1, 28, 28, 1).astype('float32') / 255.0
X_test = X_test.reshape(-1, 28, 28, 1).astype('float32') / 255.0
# 모델 구성
autoencoder = Sequential()
# Encoder: 28x28x1 -> 7x7x8로 압축
autoencoder.add(Conv2D(16, kernel_size=3, padding='same', activation='relu', input_shape=(28, 28, 1)))
autoencoder.add(MaxPooling2D(pool_size=2, padding='same'))
autoencoder.add(Conv2D(8, kernel_size=3, padding='same', activation='relu'))
autoencoder.add(MaxPooling2D(pool_size=2, padding='same'))
# Decoder: 7x7x8 -> 28x28x1로 복원
autoencoder.add(Conv2D(8, kernel_size=3, padding='same', activation='relu'))
autoencoder.add(UpSampling2D())
autoencoder.add(Conv2D(16, kernel_size=3, padding='same', activation='relu'))
autoencoder.add(UpSampling2D())
# 최종 출력층: 입력과 동일한 범위를 위해 Sigmoid 사용
autoencoder.add(Conv2D(1, kernel_size=3, padding='same', activation='sigmoid'))
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
autoencoder.fit(X_train, X_train, epochs=50, batch_size=128, validation_data=(X_test, X_test))
2. 오토인코더의 변형들
2-1 Sparse Autoencoder (희소 오토인코더)
잠재 공간의 뉴런 중 일부만 활성화(0이 아닌 값)되도록 제약을 주는 방식입니다.
- 일반 AE: 단순히 데이터를 복사하는 '복사기'가 되기 쉽습니다.
- Sparse AE: 꼭 필요한 뉴런만 사용해야 하므로, 데이터 내의 훨씬 더 유의미하고 독립적인 특징(Feature)을 추출합니다.
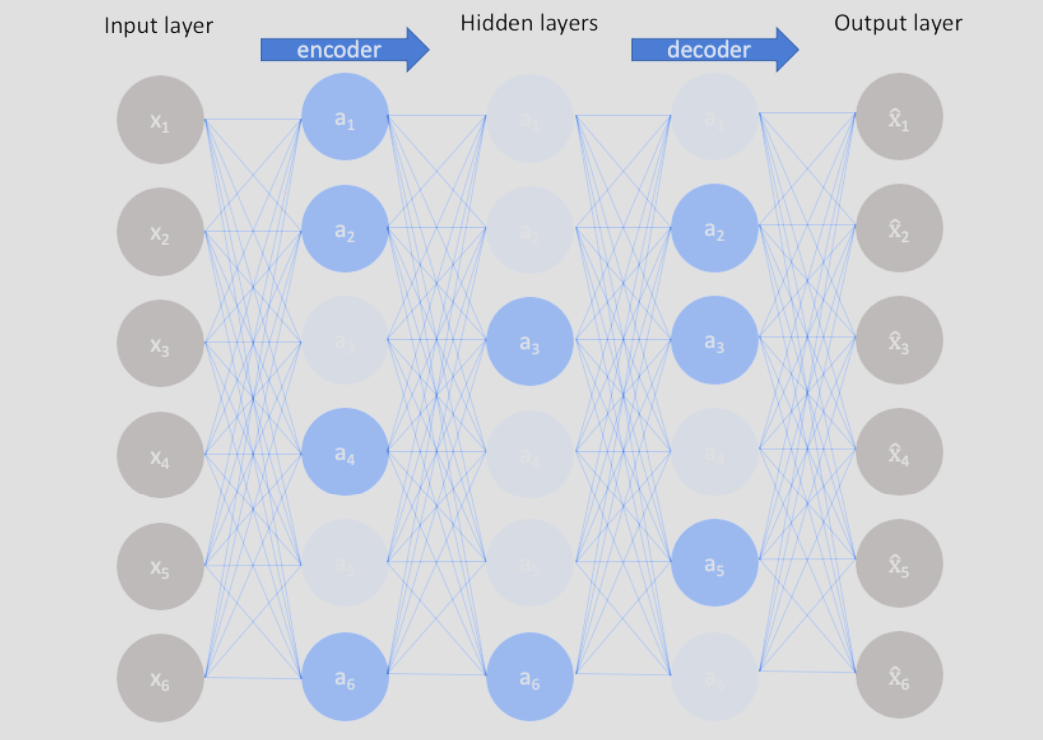
2-2 Denoising Autoencoder (DAE, 노이즈 제거 오토인코더)
입력 데이터에 의도적으로 노이즈를 섞은 후, '깨끗한 원본'으로 복원하도록 학습합니다.
- 학습 원리: 손상된 데이터에서 본질적인 패턴을 찾아내야 하므로 매우 강건(Robust)한 특징 학습이 가능해집니다.

3. PyTorch를 이용한 심화 구현: DAE & 이미지 검색
CIFAR-10 데이터를 활용하여 더 깊은 구조의 오토인코더를 구현해 봅니다. 여기서는 GELU 활성화 함수를 사용합니다.
왜 GELU(Gaussian Error Linear Unit)인가?
- 부드러움: 0 부근에서 미분이 연속적이라 학습이 안정적입니다.
- 죽은 뉴런 방지: ReLU와 달리 작은 음수 값도 통과시켜 정보 손실을 줄입니다.
- 성능: 최신 트랜스포머(BERT, GPT) 모델에서 검증된 우수한 성능을 보여줍니다.
import torch.nn as nn
class Encoder(nn.Module):
def __init__(self, num_input_channels, base_channel_size, latent_dim):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(num_input_channels, base_channel_size, kernel_size=3, padding=1, stride=2), # 16x16
nn.GELU(),
nn.Conv2d(base_channel_size, base_channel_size, kernel_size=3, padding=1),
nn.GELU(),
nn.Conv2d(base_channel_size, 2 * base_channel_size, kernel_size=3, padding=1, stride=2), # 8x8
nn.GELU(),
nn.Flatten(),
nn.Linear(2 * 16 * base_channel_size, latent_dim)
)
def forward(self, x): return self.net(x)
class Decoder(nn.Module):
def __init__(self, num_input_channels, base_channel_size, latent_dim):
super().__init__()
self.linear = nn.Sequential(nn.Linear(latent_dim, 2 * 16 * base_channel_size), nn.GELU())
self.net = nn.Sequential(
nn.ConvTranspose2d(2*base_channel_size, 2*base_channel_size, kernel_size=3, output_padding=1, padding=1, stride=2),
nn.GELU(),
nn.ConvTranspose2d(2 * base_channel_size, base_channel_size, kernel_size=3, output_padding=1, padding=1, stride=2),
nn.GELU(),
nn.ConvTranspose2d(base_channel_size, num_input_channels, kernel_size=3, output_padding=1, padding=1, stride=2),
nn.Tanh(), # 출력을 -1 ~ 1 사이로 제어
)
def forward(self, x):
x = self.linear(x)
x = x.reshape(x.shape[0], -1, 4, 4)
return self.net(x)
4. 응용: 유사 이미지 찾기 (Similarity Search)
학습된 오토인코더의 인코더가 생성한 잠재 벡터(Embedding) 간의 거리를 계산하면, 시각적으로 유사한 이미지를 찾을 수 있습니다.
def find_similar_images(query_image, query_embed, key_images, key_embeds, k=7):
# 유클리디안 거리 계산 (L2 Norm)
dist = torch.cdist(query_embed[None, :], key_embeds, p=2).squeeze(0)
# 가장 거리가 가까운(비슷한) 이미지 추출
_, topk_indices = torch.topk(dist, k, largest=False)
topk_images = torch.cat([query_image[None], key_images[topk_indices.cpu()]], dim=0)
imshow(topk_images, f'Top={k} Similar Images')
5. 의료 데이터 적용: MedMNIST (PathMNIST)
오토인코더는 일반 사진뿐만 아니라 의료용 병리 이미지(PathMNIST)에서도 특징 추출기로 훌륭하게 작동합니다. 노이즈 제거 및 차원 축소를 통해 의료 데이터 분석의 효율을 높일 수 있습니다.
import medmnist
from medmnist import INFO
# PathMNIST 데이터 로드 및 학습 (위 Autoencoder 모델 재사용)
pathmnist_info = medmnist.INFO['pathmnist']
DataClass = getattr(medmnist, pathmnist_info['python_class'])
# ... 데이터로더 설정 후 train 함수 실행
마무리
오토인코더는 단순한 복사 모델이 아닙니다. 데이터의 '본질적 특징'을 추출하는 아주 강력한 도구입니다.
- 차원 축소 및 시각화
- 노이즈 제거 (Denoising)
- 유사도 기반 검색
- 이상 탐지 (Anomaly Detection)
'개념 정리 step2 > 멀티모달(Multi-modal)' 카테고리의 다른 글
| [멀티모달] Multimodal Learning 정리 (0) | 2026.02.10 |
|---|---|
| [생성형 AI] GAN와 DCGAN 개념 정리와 실습 (0) | 2026.01.31 |
| [Deep Learning] 동영상 데이터 분석: 3D CNN과 수화 인식 실습 (0) | 2026.01.29 |
| [Deep Learning] Vision Transformer(ViT) Multi-Branch 구현 실습 (0) | 2026.01.23 |
| [NLP] KLUE-BERT 기반 멀티레이블 혐오 표현 분류 실습 (0) | 2026.01.22 |