안녕하세요!
오늘은 정확도 중심의 CNN 모델들이 가진 한계를 실생활 서비스 관점에서 재해석하고, 경량화 모델인 MobileNet의 핵심 구조 분석 및 실험 결과에 대한 블로그를 작성해 보도록 하겠습니다.
참고 논문: https://arxiv.org/abs/1704.04861
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
We present a class of efficient models called MobileNets for mobile and embedded vision applications. MobileNets are based on a streamlined architecture that uses depth-wise separable convolutions to build light weight deep neural networks. We introduce tw
arxiv.org
실험 테스트 깃 허브 링크: https://github.com/MeatHub/Team-Assignment---MobileNet
GitHub - MeatHub/Team-Assignment---MobileNet: 본 리포지토리는 대표적인 경량 컴퓨터 비전 모델인 MobileNet의
본 리포지토리는 대표적인 경량 컴퓨터 비전 모델인 MobileNet의 구조적 특징을 분석하고, 공개 데이터셋을 활용한 이미지 분류 실험 및 성능 분석 내용을 담고 있습니다. - MeatHub/Team-Assignment---Mobil
github.com
MobileNet: 논문 리뷰
이 논문은 모바일 및 임베디드 비전 애플리케이션을 위한 효율적인 Convolutional Neural Network인 MobileNets를 제안합니다.
MobileNet은 구글에서 제안한 혁신적인 아키텍처로, 제한된 자원을 가진 모바일 환경에서도 강력한 성능을 발휘할 수 있도록 설계되었습니다. 이 모델의 핵심은 정확도를 최대한 유지하면서 모델의 크기와 연산량을 획기적으로 줄이는 것에 있습니다.
1. 문제 의식 (Motivation)
논문의 저자들은 당시 CNN 모델들이 처한 현실적인 한계를 해결하고자 했습니다.
- CNN의 중량화: ImageNet 대회 이후 CNN 모델들은 정확도를 높이기 위해 층을 더 깊게 쌓고 모델을 무겁게 만드는 데 집중했습니다.
- 실행 환경의 한계: 이러한 모델들은 고성능 GPU 환경에서는 잘 돌아가지만, 연산량(FLOPs)과 파라미터 수의 급증으로 인해 모바일, IoT, 임베디드 기기에서는 사실상 구동이 불가능한 수준이었습니다.
- 핵심 질문: "똑똑하지만 비싸고 무거운 모델을 어떻게 하면 실생활(모바일)에서 가볍고 빠르게 쓸 수 있을까?"
2. 핵심 방법론: Depthwise Separable Convolution
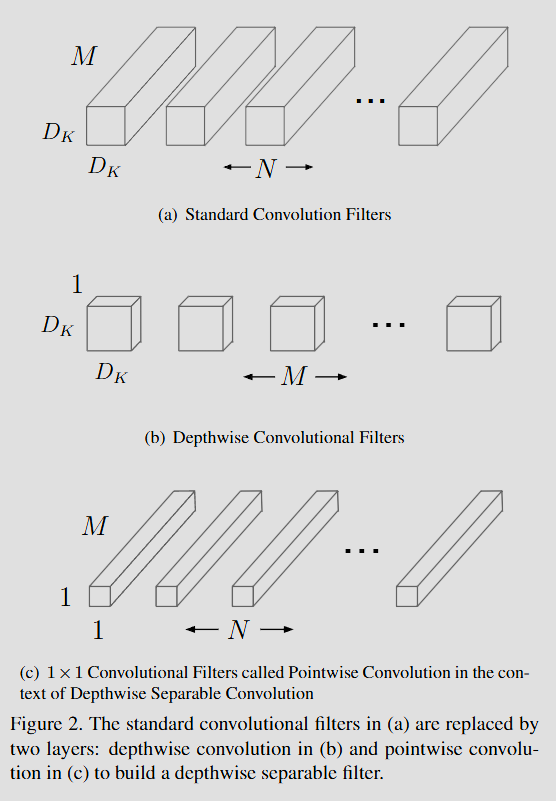
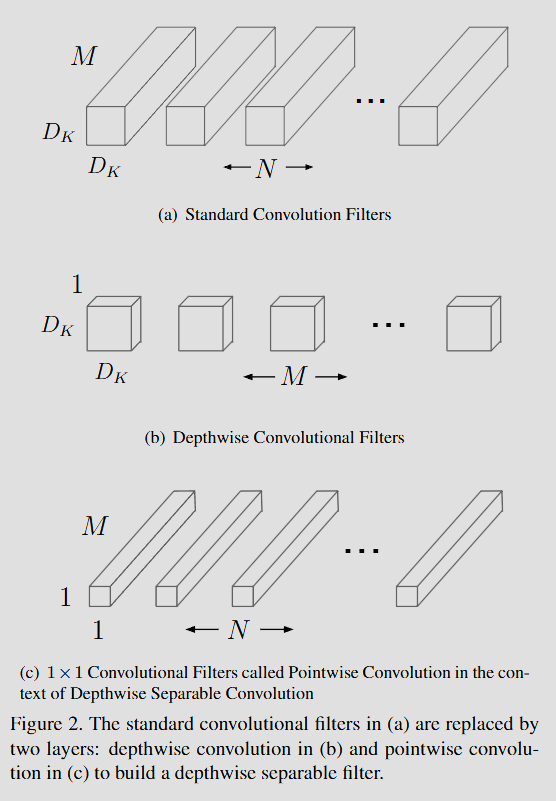
MobileNet의 가장 큰 특징은 표준 Convolution을 Depthwise Convolution과 Pointwise Convolution으로 분리한 것입니다.
A. 표준 Convolution (Standard Convolution)
필터링과 조합을 동시에 수행하며 계산 비용이 높습니다.
- 계산 비용: $D_K \cdot D_K \cdot M \cdot N \cdot D_F \cdot D_F$
- $D_K$: 커널 크기
- $M$: 입력 채널 수 / $N$: 출력 채널 수
- $D_F$: 피처맵 크기
B. Depthwise Separable Convolution
- Depthwise Convolution: 각 입력 채널에 하나의 필터만 적용하여 공간적 특징을 추출합니다. (필터링만 수행)
- $$\hat{G}_{k,l,m} = \sum_{i,j}\hat{K}_{i,j,m} \cdot F_{k+i-1,l+j-1,m}$$
- 계산 비용: $D_K \cdot D_K \cdot M \cdot D_F \cdot D_F$
- Pointwise Convolution (1x1 Conv): Depthwise의 출력을 선형 조합하여 새로운 특징을 생성합니다. (채널 간 조합 수행)
- 계산 비용: $M \cdot N \cdot D_F \cdot D_F$
💡 효율성 결과:
전체 계산 비용은 위 두 단계의 합산이며, 표준 대비 약 $\frac{1}{N} + \frac{1}{D_K^2}$ 배의 연산 감소 효과가 있습니다. 3x3 커널 사용 시 연산량이 8~9배 감소합니다.
3. 모델 최적화를 위한 두 가지 하이퍼파라미터
MobileNet은 모델 빌더가 Latency와 Accuracy 사이의 균형을 직접 조절할 수 있도록 두 가지 전역 하이퍼파라미터를 제공합니다.
| 파라미터 | 명칭 | 역할 | 효과 |
| $\alpha$ | Width Multiplier | 네트워크의 채널 수를 균일하게 감소 | 계산 비용 및 파라미터 수를 약 $\alpha^2$ 배 감소 |
| $\rho$ | Resolution Multiplier | 입력 이미지 및 내부 피처맵 해상도 조절 | 연산량을 $\rho^2$ 배 감소 |
4. 실험 및 성능 비교 (ImageNet 기준)
MobileNet은 압도적인 효율성을 숫자로 증명했습니다.
- Full Convolution vs MobileNet:
- Parameters: 29.3M → 4.2M (약 7배 감소)
- Mult-Adds: 4,866M → 569M (약 8.5배 감소)
- Accuracy: 71.7% → 70.6% (단 1.1% 감소)
타 모델과의 성능 비교
- VGG16 대비: 정확도는 비슷하지만 모델 크기는 32배 작고, 연산량은 27배 적음.
- GoogleNet 대비: 정확도는 더 높으면서 연산량은 2.5배 적음.
- AlexNet 대비: 정확도는 4% 높으면서 45배 더 작고, 연산량은 9.4배 적음.
5. 다양한 애플리케이션 활용 사례
MobileNet은 일반적인 이미지 분류 외에도 다양한 비전 작업에서 그 범용성을 입증했습니다.
- 세분화된 분류 (Stanford Dogs): 훨씬 적은 연산량으로 Inception V3 수준의 SOTA 성능 달성.
- 대규모 지리 위치 파악 (PlaNet): 기존 모델을 크게 능가하며 파라미터 수 대폭 절감.
- 얼굴 속성 분류: 지식 증류(Distillation)와 결합하여 대규모 모델을 1%의 연산량으로 압축.
- 객체 탐지 (Object Detection): Faster-RCNN 및 SSD의 백본으로 사용되어 효율적인 mAP 달성.
- 얼굴 임베딩: FaceNet의 출력을 모방하여 모바일용 얼굴 인식 모델 구현.
6. 결론
MobileNet은 단순한 경량 모델을 넘어, 사용자가 자신의 시스템 환경에 맞춰 성능과 속도를 유연하게 조절할 수 있는 프레임워크를 제공했다는 점에서 큰 의미가 있습니다. 특히 전체 연산의 95%가 1x1 Convolution에 집중되어 있어 GEMM(최적화된 선형 대수 알고리즘)을 매우 효율적으로 활용할 수 있다는 점이 실전 배포에서 큰 강점으로 작용합니다.
MobileNet 실험
1. 실험 개요 및 데이터셋 (Dataset)
실제 농가에서 활용 가능한 실시간 진단 모델을 목표로, 방대한 식물 병해 데이터를 학습에 활용했습니다.
- 데이터셋: New Plant Diseases Dataset (Augmented)
- 클래스 구성: 총 38개 (사과, 토마토, 포도, 감자 등 10개 작물의 병해 및 정상 상태)
- 데이터 규모: 총 70,295장
- 학습 데이터 (Train): 56,236장 (80%)
- 검증 데이터 (Val): 14,059장 (20%)
- 전처리: $224 \times 224$ 리사이징 및 ImageNet 표준 정규화 적용
2. 모델 설계 및 학습 전략
모바일 기기의 성능 제한을 고려하여 MobileNet V2를 백본(Backbone)으로 채택하고, 2단계에 걸친 최적화 전략을 수행했습니다.
🛠 핵심 아키텍처
- Depthwise Separable Convolution: 연산량을 표준 합성곱 대비 8~9배 절감하여 실시간 추론 속도 확보.
- Pre-trained Model: ImageNet으로 사전 학습된 가중치를 활용하여 학습 효율 극대화.
2단계 학습 프로세스
| 단계 | 전략 | 설정 | 주요 목적 |
| Stage 1 | 전이 학습 | Backbone 동결, LR=0.001, 10 Epoch | 분류기(Classifier)의 기초 학습 |
| Stage 2 | 파인 튜닝 | 전 레이어 해제, LR=0.00001, 5 Epoch | 모델 전체의 미세 조정 및 최적화 |
3. 실험 결과 분석 (Result Analysis)
15회(10+5)의 에포크 수행 결과, 경량 모델임에도 불구하고 매우 높은 정밀도를 달성했습니다.
- 최종 검증 정확도 (Accuracy): 99.37%
- 학습 곡선 (Learning Curve):
- Stage 1에서 이미 95% 이상의 성능을 확보했으며, Stage 2 파인 튜닝 도입 직후 Loss가 급격히 하락하며 99%대에 안착했습니다.
- 세부 지표:
- 대부분의 클래스에서 F1-Score 1.00에 근접한 성능을 보였으나, 옥수수(Corn)의 일부 병해(Gray Leaf Spot vs Northern Leaf Blight)에서 미세한 혼동이 관찰되었습니다.
4. 최종 결론
- 압도적인 효율성: 38개의 복잡한 클래스를 분류함에 있어 MobileNet V2는 약 99.37%라는 놀라운 정확도를 기록했습니다.
- 실전 적용 가능성: 모델 크기가 작고 추론 속도가 빨라 저사양 스마트폰이나 IoT 기기에서도 지연 시간 없는 실시간 병해 진단이 가능함을 입증했습니다.
- 최적화의 승리: 단순히 층을 쌓는 것보다 사전 학습 모델 활용 + 정교한 파인 튜닝 전략이 경량 모델의 성능을 어디까지 끌어올릴 수 있는지 확인한 실험이었습니다.
'1. AI 논문 + 모델 분석 > AI 모델 분석' 카테고리의 다른 글
| [LLaVA] 학습 스크립트로 보는 멀티모달 모델의 구현 원리 (0) | 2026.02.20 |
|---|---|
| [OCR] PaddleOCR 축산물 이력번호 인식 모델 학습 성공 과정 (0) | 2026.02.07 |
| [Meat-A-Eye] 파인튜닝을 통한 정확도 70% → 90% 개선 정리 (0) | 2026.02.05 |
| [OCR] PaddleOCR Rec 학습 원리 및 소량 데이터 분석 (0) | 2026.02.04 |
| EfficientNet-B0와 Grad-CAM 분석해보기 (0) | 2026.01.18 |