안녕하세요!
자연어 처리(Natural Language Processing)는 인간의 언어를 기계가 이해하고 생성하도록 만드는 분야입니다. 단순히 단어를 나열하는 것을 넘어, 문맥을 파악하고 새로운 문장을 만들어내는 일련의 과정에는 수많은 기술적 도약이 있었습니다.
1. NLU와 NLG
자연어 이해 (NLU, Natural Language Understanding)
NLU는 기계가 인간 언어의 의미를 해석하는 기술입니다. 단순히 텍스트를 읽는 것이 아니라 문맥을 파악하는 것이 핵심입니다.
- 주요 과업: 개체명 인식(NER), 감성 분석, 문장 의도 분류, 의미적 유사성 판단.
- 핵심: 기계 학습과 딥러닝을 통해 문장 속에 숨겨진 의도와 구조를 추론합니다.
자연어 생성 (NLG, Natural Language Generation)
NLG는 데이터를 바탕으로 사람이 이해할 수 있는 자연스러운 문장을 생성하는 기술입니다.
- 단계: 데이터 해석 → 문장 계획 → 언어 실현.
- 최신 트렌드: GPT와 같은 대규모 언어 모델(LLM)의 등장으로 창의적이고 정교한 텍스트 생성이 가능해졌습니다.
2. 시퀀스투시퀀스 (Seq2Seq) 모델의 이해
Seq2Seq는 입력 시퀀스를 받아 출력 시퀀스를 만드는 구조로, 번역기나 요약기에 주로 사용됩니다. 논문 참고
Sequence to Sequence Learning with Neural Networks
Deep Neural Networks (DNNs) are powerful models that have achieved excellent performance on difficult learning tasks. Although DNNs work well whenever large labeled training sets are available, they cannot be used to map sequences to sequences. In this pap
arxiv.org
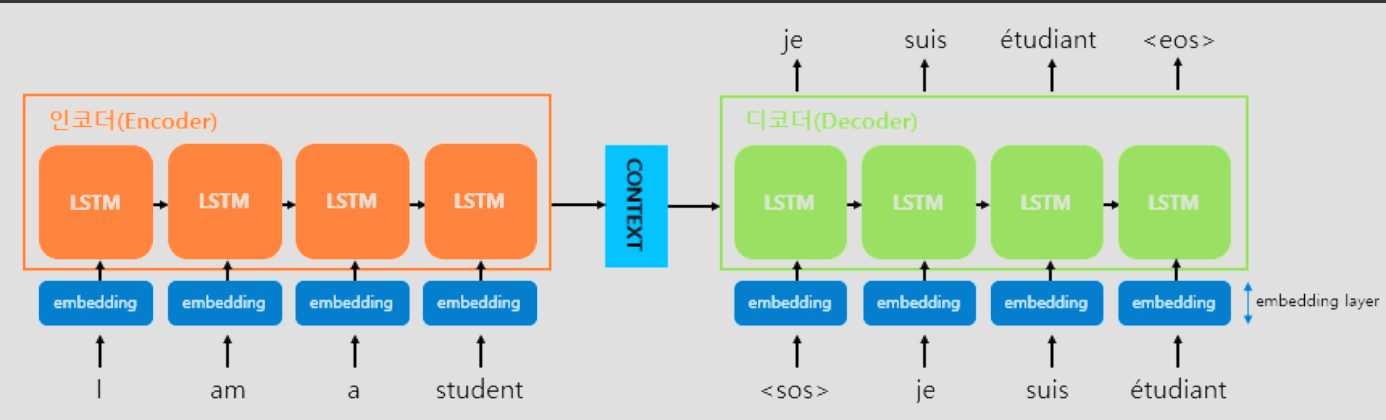
인코더 (Encoder)
입력 문장의 정보를 압축하여 하나의 고정된 크기의 벡터인 컨텍스트 벡터(Context Vector)를 생성합니다.
- 입력 시퀀스를 단어 단위로 처리합니다.
- RNN 계열(LSTM, GRU) 구조를 사용하여 단어를 순차적으로 읽으며 은닉 상태(Hidden State)를 업데이트합니다.
- 마지막 단어까지 읽은 후의 최종 상태가 바로 문장의 의미가 압축된 컨텍스트 벡터가 됩니다.
디코더 (Decoder)
인코더가 만든 컨텍스트 벡터를 바탕으로 새로운 문장을 생성합니다.
- 컨텍스트 벡터를 초기 입력으로 받습니다.
- 이전 단계에서 생성한 단어를 다음 단계의 입력으로 사용하는 자기회귀(Autoregressive) 방식을 취합니다.
- 종료 토큰(<eos>)이 나올 때까지 문장을 계속 생성합니다.
Seq2Seq의 한계점
- 정보 손실: 긴 문장이라도 하나의 고정된 벡터에 압축해야 하므로 정보가 유실되는 병목 현상이 발생합니다.
- 기울기 소실: RNN 구조 특성상 문장이 길어질수록 앞부분의 정보를 잃어버리는 장기 의존성 문제가 있습니다.
3. 어텐션(Attention)과 임베딩의 진화
어텐션 메커니즘의 등장
기존 모델의 한계를 극복하기 위해, 출력 단어를 예측하는 매 순간 입력 문장의 전체 단어를 다시 한 번 훑어보는 기술입니다. 모든 단어를 동일하게 보는 것이 아니라, 관련이 깊은 단어에 더 높은 가중치(집중도)를 부여합니다.
단어 임베딩과 문맥적 의미
단어 임베딩은 단어를 고차원 벡터 공간에 배치하는 과정입니다.
- 공동출현 정보: "사과"라는 단어가 "귤"과 함께 쓰이면 '과일'의 의미로, "사죄"와 함께 쓰이면 '행위'의 의미로 학습됩니다.
- 벡터 이동: 학습 과정에서 문맥에 따라 단어 벡터의 위치가 조정되며, 비슷한 문맥에서 쓰이는 단어끼리 가까워집니다.
토큰화와 패딩 (Tokenization & Padding)
모델은 가변적인 문장 길이를 직접 처리할 수 없으므로 행렬 연산을 위해 사이즈를 맞춰야 합니다.
- 토큰화: 문장을 최소 단위(토큰)로 분리하고 숫자 벡터로 변환합니다.
- 패딩: 짧은 문장의 빈 곳을 PAD 토큰으로 채워 모든 문장의 길이를 동일하게 맞춥니다. 이는 GPU 병렬 연산을 효율적으로 수행하기 위한 필수 단계입니다.
4. 트랜스포머의 핵심: 멀티-헤드 셀프 어텐션
셀프 어텐션 (Self-Attention)
문장 내의 단어들끼리 서로의 관계를 계산하는 방식입니다. 이를 위해 쿼리(Query), 키(Key), 값(Value)이라는 세 가지 개념을 사용합니다.
- Query (Q): "내가 지금 집중하고 있는 단어는 무엇인가?" (질문)
- Key (K): "나와 다른 단어들이 얼마나 관련이 있는가?" (비교 대상)
- Value (V): "관련이 있다면 어떤 정보를 가져올 것인가?" (실제 내용)
어텐션 스코어와 스케일링
- 유사도 계산: $Q$와 $K$를 내적($Dot-product$)하여 유사도를 구합니다.
- 스케일링: 값이 커져서 학습이 불안정해지는 것을 막기 위해 $\sqrt{d_k}$로 나눕니다.
- 소프트맥스: 결과를 0~1 사이의 확률 값으로 변환하여 가중치를 정합니다. 이 때 PAD 토큰은 $-\infty$ 처리를 하여 가중치가 0이 되도록 마스킹합니다.
- 최종 가중합: 가중치를 $V$에 곱하여 문맥이 반영된 새로운 벡터를 얻습니다.
멀티-헤드 어텐션 (Multi-Head Attention)
512차원의 임베딩을 한 번에 처리하지 않고, 8개의 헤드(각 64차원)로 나누어 병렬 처리합니다.
- 각 헤드는 서로 다른 시선(문법적 관계, 의미적 관계 등)으로 문장을 분석합니다.
- 나중에 이 결과들을 다시 하나로 합쳐서(Concatenate) 더 풍부한 표현을 만들어냅니다.
5. 실습 코드로 보는 어텐션 연산 과정 (NumPy)
아래 코드는 문장 배치 처리부터 멀티-헤드 분할, 스케일드 닷-프로덕트 어텐션 수행 과정을 NumPy로 구현한 예시입니다.
import numpy as np
# 1. 환경 설정 및 임베딩 정의
np.set_printoptions(precision=4, suppress=True)
embedding_dict = {
'<sos>': np.random.rand(512),
'<eos>': np.random.rand(512),
'커피': np.random.rand(512),
'한잔': np.random.rand(512),
'어때': np.random.rand(512),
'오늘': np.random.rand(512),
'날씨': np.random.rand(512),
'좋네': np.random.rand(512),
'옷이': np.random.rand(512),
'어울려요': np.random.rand(512),
'PAD': np.zeros(512)
}
# 2. 입력 문장 구성 및 배치 임베딩 생성
sentences = [
['<sos>', '커피', '한잔', '어때', '<eos>'],
['<sos>', '오늘', '날씨', '좋네', '<eos>'],
['<sos>', '옷이', '어울려요', '<eos>', 'PAD']
]
embeddings = np.array([[embedding_dict[token] for token in sentence] for sentence in sentences])
# 3. 멀티-헤드 분할 (8 Heads)
num_heads = 8
head_dim = 512 // num_heads
heads = np.split(embeddings, num_heads, axis=2)
queries = heads.copy()
keys = [head.transpose(0, 2, 1) for head in heads]
values = heads.copy()
# 4. 소프트맥스 함수 정의
def softmax(x):
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
# 5. 어텐션 루프 수행 (스케일링 및 마스킹 포함)
scaling_factor = np.sqrt(head_dim)
restored_heads = []
for i in range(num_heads):
query = queries[i]
key = keys[i]
value = values[i]
# 유사도 계산 및 스케일링
attention_scores = np.matmul(query, key) / scaling_factor
# 패딩 마스크 적용 (PAD 토큰의 영향을 0으로 만듦)
mask = np.array([[token == 'PAD' for token in sentence] for sentence in sentences])
mask = mask[:, np.newaxis, :]
scaled_scores = np.where(mask, -np.inf, attention_scores)
# 가중치 계산 및 Value 적용
attention_weights = softmax(scaled_scores)
restored_head = np.matmul(attention_weights, value)
restored_heads.append(restored_head)
# 6. 헤드 결합 (Final Output)
final_output = np.concatenate(restored_heads, axis=2)
# 결과 확인
tokens_of_interest = ['커피', '한잔', '어때']
indices = [sentences[0].index(token) for token in tokens_of_interest]
print("어텐션 이후 결과 (문맥 반영된 벡터 평균):")
print(np.mean(final_output[0, indices, :], axis=1))
코드 요약12
- 차원 맞춤: 입력 임베딩을 헤드 수만큼 나누어 병렬 연산 구조를 만듭니다.
- 마스킹: np.where(mask, -np.inf, attention_scores)를 통해 패딩 토큰이 어텐션 결과에 영향을 주지 못하도록 처리합니다.
- 결합: 개별적으로 연산된 헤드들을 다시 concatenate하여 원래의 512차원 벡터로 복원합니다.
마치며
자연어 처리는 입력의 가변성을 어떻게 효율적으로 다루고, 단어 사이의 관계를 얼마나 정교하게 수치화하느냐의 싸움입니다. Seq2Seq에서 트랜스포머로의 진화는 이 두 문제를 병렬 연산과 어텐션 메커니즘으로 우아하게 해결한 과정이라고 볼 수 있습니다.
'개념 정리 step2 > 멀티모달(Multi-modal)' 카테고리의 다른 글
| [NLP] KLUE-BERT 기반 멀티레이블 혐오 표현 분류 실습 (0) | 2026.01.22 |
|---|---|
| [Deep Learning] 트랜스포머(Transformer): NLP 아키텍처 정리 (0) | 2026.01.19 |
| [RNN] 시퀀스 데이터와 순환 신경망(RNN) 학습 정리 (1) | 2026.01.15 |
| [NLP] 단어 임베딩: Word2Vec부터 FastText, GloVe (0) | 2026.01.14 |
| [NLP 기초] 자연어 처리의 시작: 토큰화와 벡터화 (0) | 2026.01.13 |